Иллюмина и BGI



Функции
●Платформы:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten и BGI-DNB-T7
●Режимы последовательности:ПЭ50, ПЭ100, ПЭ150, ПЭ250
●Контроль качества библиотек перед секвенированием
●Доставка данных секвенирования и контроль качества:доставка отчета контроля качества и необработанных данных в формате fastq после демультиплексирования и фильтрации чтений Q30.
Преимущества сервиса
●Универсальность услуг секвенирования:клиент может выбрать секвенирование по дорожке, проточной кювете или объему данных.
●Универсальность платформ:Библиотеки DNB можно перенести на платформы Illumina
●Обширный опыт работы на платформе секвенирования Illumina:с тысячами закрытых проектов с различными видами.
●Доставка отчета по контролю качества секвенирования:с показателями качества, точностью данных и общей производительностью проекта секвенирования.
●Зрелый процесс секвенирования:с коротким сроком оборота.
●Строгий контроль качества: мы реализуем строгие требования к контролю качества, чтобы гарантировать получение неизменно высококачественных результатов.
Пример требований*
Частичное последовательность дорожек
| Объем данных (X) | Концентрация (кПЦР/нМ) | Объем |
| Х ≤ 50 Гб | ≥ 2 нМ | ≥ 20 мкл |
| 50 Гб ≤ X < 100 Гб | ≥ 3 нМ | ≥ 20 мкл |
| Х ≥ 100 Гб | ≥ 4 нМ | ≥ 20 мкл |
Однополосный (Illumina)
| Платформа | Концентрация (кПЦР/нМ) | Объем |
| HiSeq X Десять | ≥ 2 нМ | ≥ 20 мкл |
| НоваСек 6000 СП | ≥ 1 нМ | ≥ 25 мкл |
| НоваСек 6000 S4 | ≥ 1,5 нМ | ≥ 25 мкл |
| НоваСек Х | ≥ 1,5 нМ | ≥ 25 мкл |
| BGI-DNBSEQ-T7 | ≥ 1,5 нМ | ≥ 25 мкл |
Помимо концентрации и общего количества, также требуется подходящая картина пиков.
Пожалуйста, свяжитесь с нами, если ваши образцы не соответствуют требованиям к исходному материалу.
Рабочий процесс обслуживания
Контроль качества библиотеки

Последовательность действий

Контроль качества данных

Доставка проекта
Отчет по контролю качества библиотеки
Отчет о качестве библиотеки предоставляется до секвенирования, оценки объема библиотеки и фрагментации.
Отчет по контролю качества секвенирования
Таблица 1. Статистика данных секвенирования.
| Идентификатор образца | БМКИД | Необработанные чтения | Необработанные данные (б.п.) | Чистое чтение (%) | К20 (%) | Q30(%) | ГК(%) |
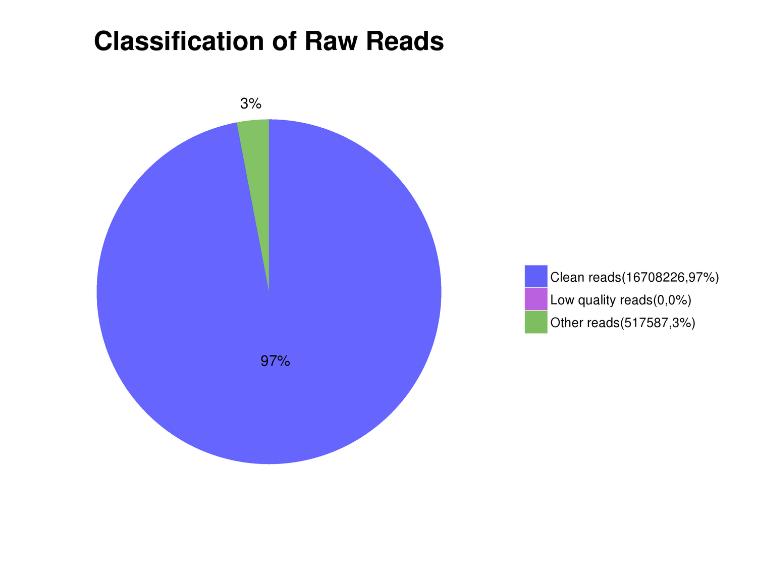
| С_01 | БМК_01 | 22 870 120 | 6 861 036 000 | 96,48 | 99,14 | 94,85 | 36,67 |
| С_02 | БМК_02 | 14 717 867 | 4 415 360 100 | 96.00 | 98,95 | 93,89 | 37.08 |
Рисунок 1. Распределение качества по прочтениям в каждом образце
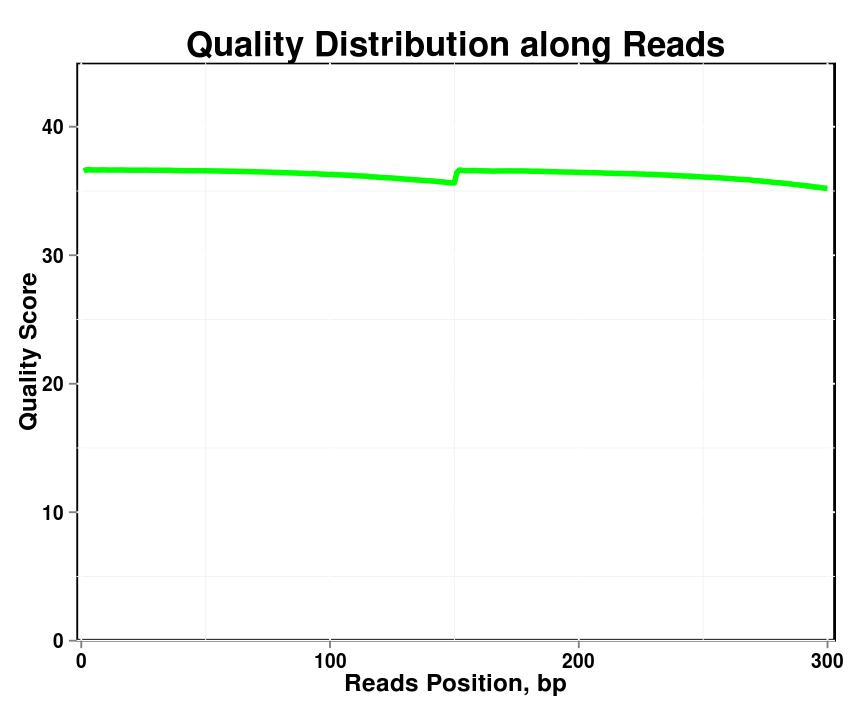
Рисунок 2. Распределение базового контента
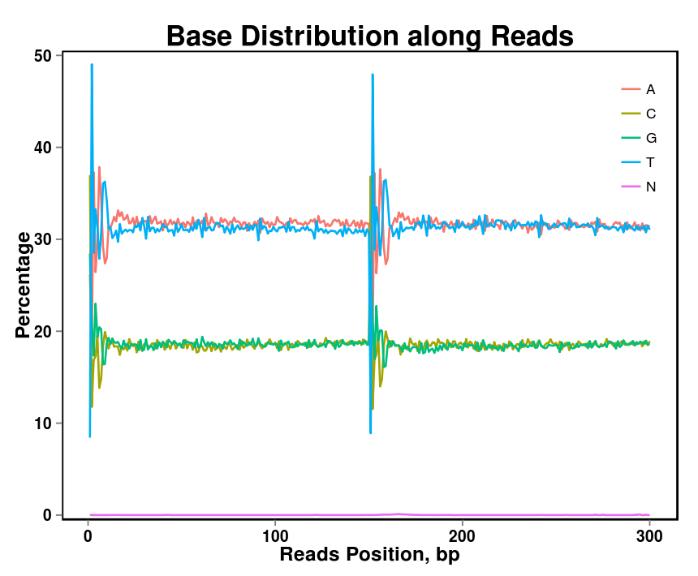
Рисунок 3. Распределение содержимого прочтений в данных секвенирования.