

ການຈັດລຳດັບ mRNA ເຕັມຄວາມຍາວ -PacBio





ຂໍ້ໄດ້ປຽບການບໍລິການ
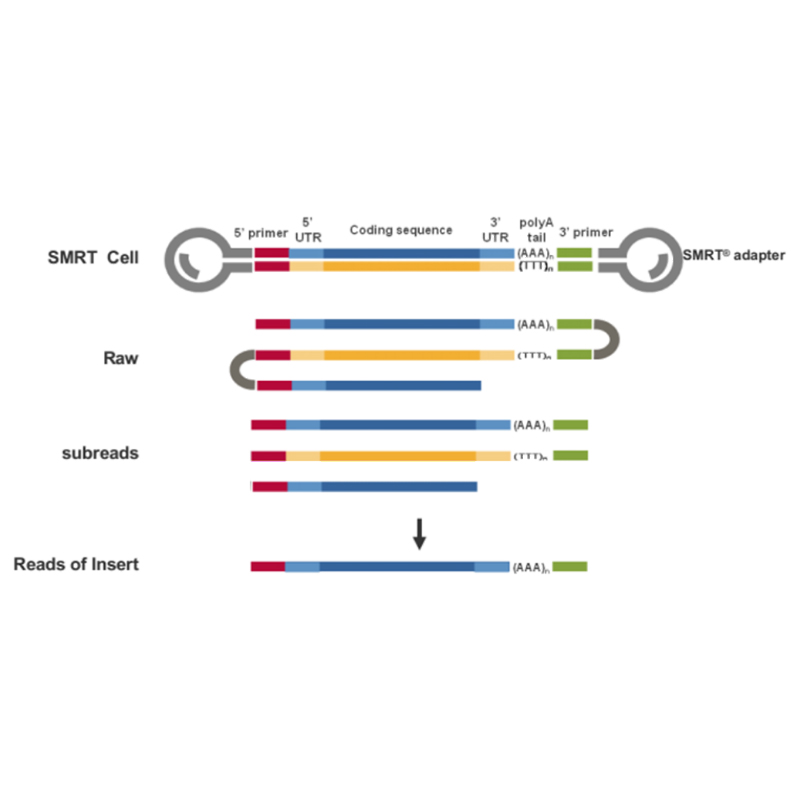
● ການອ່ານອອກໂດຍກົງຂອງໂມເລກຸນ cDNA ທີ່ມີຄວາມຍາວເຕັມຈາກ 3'- ປາຍຫາ 5'- ທ້າຍ
● ຄວາມລະອຽດລະດັບ iso-form ໃນໂຄງສ້າງລໍາດັບ
● ການຖອດຂໍ້ຄວາມທີ່ມີຄວາມຖືກຕ້ອງສູງ ແລະຄວາມຖືກຕ້ອງ
●ເຂົ້າກັນໄດ້ສູງກັບຊະນິດ vaiours
● ຄວາມອາດສາມາດຈັດລໍາດັບຂະຫນາດໃຫຍ່ທີ່ມີ 4 ແພລະຕະຟອມລໍາດັບ PacBio Sequel II ທີ່ຕິດຕັ້ງ
● ມີປະສົບການສູງກັບຫຼາຍກວ່າ 700 ໂຄງການລໍາດັບ RNA ທີ່ອີງໃສ່ Pacbio
● ການຈັດສົ່ງຜົນໄດ້ຮັບໂດຍອີງໃສ່ BMKCloud: ການຂຸດຄົ້ນຂໍ້ມູນແບບກຳນົດເອງທີ່ມີຢູ່ໃນເວທີ.
● ການບໍລິການຫຼັງການຂາຍມີເວລາ 3 ເດືອນຫຼັງຈາກໂຄງການສໍາເລັດ
ຂໍ້ມູນຈໍາເພາະການບໍລິການ
ເວທີ: PacBio Sequel II
ຫ້ອງສະໝຸດແບບລຳດັບ: ຫ້ອງສະໝຸດ mRNA ທີ່ອຸດົມດ້ວຍ Poly A
ຂໍ້ມູນຜົນຜະລິດທີ່ແນະນໍາ: 20 Gb/ຕົວຢ່າງ (ຂຶ້ນກັບຊະນິດ)
FLNC (%): ≥75%
*FLNC: ຄວາມຍາວເຕັມຂອງ transcipts ທີ່ບໍ່ແມ່ນchimeric
ການວິເຄາະ bioinformatics
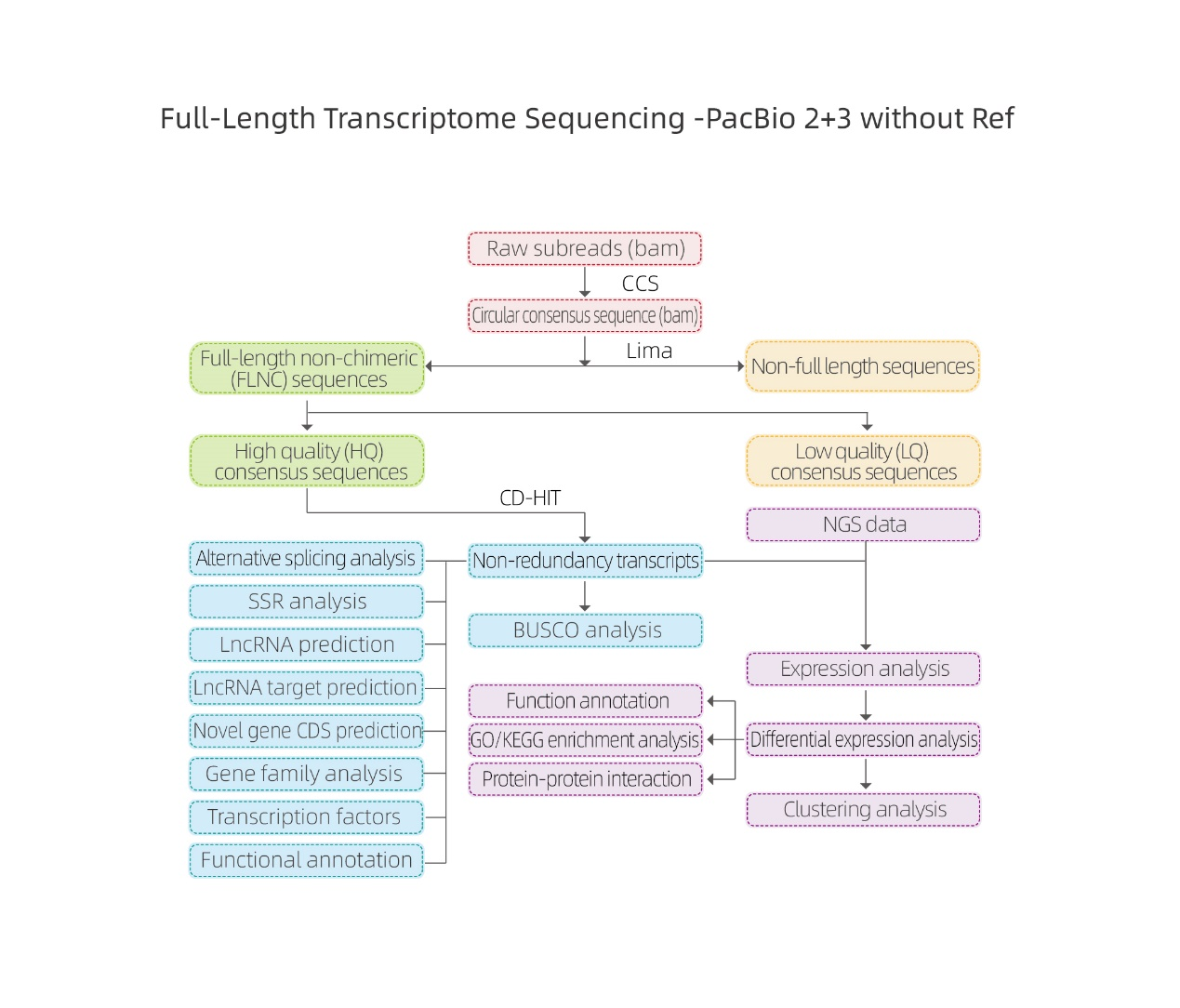
● ການປະມວນຜົນຂໍ້ມູນດິບ
● ການລະບຸການຖອດຂໍ້ຄວາມ
● ໂຄງສ້າງລໍາດັບ
● ປະລິມານການສະແດງອອກ
● Function Annotation
ຄວາມຕ້ອງການຕົວຢ່າງແລະການຈັດສົ່ງ
ຄວາມຕ້ອງການຕົວຢ່າງ:
Nucleotides:
| Conc.(ng/μl) | ປະລິມານ (μg) | ຄວາມບໍລິສຸດ | ຄວາມຊື່ສັດ |
| ≥ 120 | ≥ 0.6 | OD260/280=1.7-2.5 OD260/230=0.5-2.5 ຈໍາກັດຫຼືບໍ່ມີການປົນເປື້ອນທາດໂປຼຕີນຫຼື DNA ທີ່ສະແດງຢູ່ໃນເຈນ. | ສໍາລັບພືດ: RIN≥7.5; ສໍາລັບສັດ: RIN≥8.0; 5.0≥ 28S/18S≥1.0; ຂອບເຂດຈໍາກັດ ຫຼືບໍ່ມີລະດັບຄວາມສູງ |
ເນື້ອເຍື່ອ: ນໍ້າໜັກ (ແຫ້ງ):≥1 g
* ສໍາລັບເນື້ອເຍື່ອຂະຫນາດນ້ອຍກວ່າ 5 ມລກ, ພວກເຮົາແນະນໍາໃຫ້ສົ່ງຕົວຢ່າງເນື້ອເຍື່ອ frozen (ໃນໄນໂຕຣເຈນຂອງແຫຼວ) flash.
ການລະງັບເຊລ:ຈຳນວນຕາລາງ = 3×106- 1×107
*ພວກເຮົາແນະນໍາໃຫ້ສົ່ງ lysate ຫ້ອງ frozen.ໃນກໍລະນີທີ່ຕາລາງນັ້ນນັບໜ້ອຍກວ່າ 5×105, ກະພິບ frozen ໃນໄນໂຕຣເຈນຂອງແຫຼວແມ່ນແນະນໍາໃຫ້, ເຊິ່ງດີກວ່າສໍາລັບການສະກັດຈຸນລະພາກ.
ຕົວຢ່າງເລືອດ:ປະລິມານ≥1ມລ
ຈຸລິນຊີ:ມະຫາຊົນ ≥ 1 g
ການຈັດສົ່ງຕົວຢ່າງທີ່ແນະນໍາ
ຕູ້ຄອນເທນເນີ:
ທໍ່ centrifuge 2 ມລ (ບໍ່ແນະນໍາໃຫ້ໃຊ້ຟອຍກົ່ວ)
ການຕິດສະຫຼາກຕົວຢ່າງ: Group+replicate ເຊັ່ນ: A1, A2, A3;B1, B2, B3......
ການຂົນສົ່ງ:
1. ນ້ຳກ້ອນແຫ້ງ: ຕົວຢ່າງຕ້ອງຖືກບັນຈຸໃສ່ຖົງ ແລະຝັງໄວ້ໃນນ້ຳກ້ອນແຫ້ງ.
2. ທໍ່ RNAstable: ຕົວຢ່າງ RNA ສາມາດຕາກແຫ້ງໃນທໍ່ສະຖຽນລະພາບ RNA (ເຊັ່ນ: RNAstable®) ແລະສົ່ງໃນອຸນຫະພູມຫ້ອງ.
ກະແສວຽກບໍລິການ

ການອອກແບບທົດລອງ
ການຈັດສົ່ງຕົວຢ່າງ
ການສະກັດເອົາ RNA
ການກໍ່ສ້າງຫໍສະຫມຸດ

ການຈັດລໍາດັບ

ການວິເຄາະຂໍ້ມູນ
ບໍລິການຫຼັງການຂາຍ
1.FLNC ການແຜ່ກະຈາຍຄວາມຍາວ
ຄວາມຍາວຂອງຄວາມຍາວຂອງການອ່ານທີ່ບໍ່ແມ່ນ Chimeric (FLNC) ຊີ້ບອກຄວາມຍາວຂອງ cDNA ໃນການກໍ່ສ້າງຫ້ອງສະຫມຸດ.ການແຜ່ກະຈາຍຄວາມຍາວ FLNC ເປັນຕົວຊີ້ວັດທີ່ສໍາຄັນໃນການປະເມີນຄຸນນະພາບຂອງການກໍ່ສ້າງຫ້ອງສະຫມຸດ.
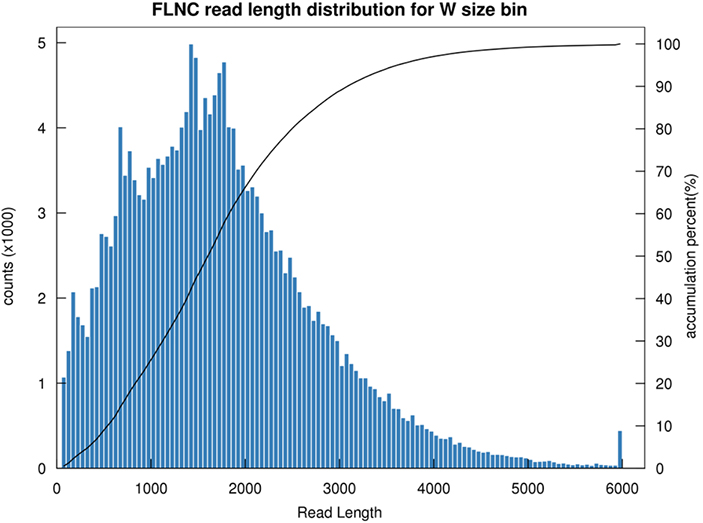
FLNC ອ່ານການແຈກຢາຍຄວາມຍາວ
2.Complete ການແຜ່ກະຈາຍຄວາມຍາວພາກພື້ນ ORF
ພວກເຮົາໃຊ້ TransDecoder ເພື່ອຄາດຄະເນພາກພື້ນລະຫັດໂປຣຕີນ ແລະລໍາດັບອາຊິດ amino ທີ່ສອດຄ້ອງກັນເພື່ອສ້າງຊຸດ unigene, ເຊິ່ງປະກອບດ້ວຍຂໍ້ມູນການຖອດຂໍ້ຄວາມທີ່ສົມບູນທີ່ບໍ່ຊໍ້າຊ້ອນໃນທຸກຕົວຢ່າງ.
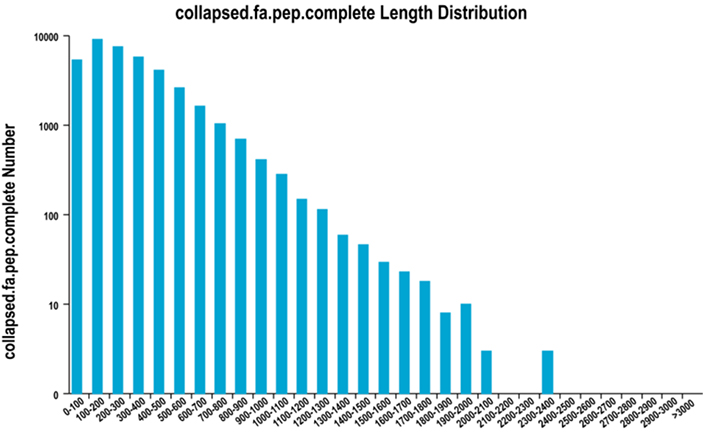
ສໍາເລັດການແຈກຢາຍຄວາມຍາວພາກພື້ນ ORF
3.KEGG ການວິເຄາະການເສີມສ້າງເສັ້ນທາງ
ຂໍ້ມູນການຖອດຂໍ້ຄວາມທີ່ສະແດງອອກແຕກຕ່າງກັນ (DETs) ສາມາດຖືກກໍານົດໂດຍການຈັດລໍາດັບຂໍ້ມູນ NGS-based RNA ຢູ່ໃນຊຸດການຖອດຂໍ້ຄວາມທີ່ມີຄວາມຍາວເຕັມທີ່ສ້າງຂຶ້ນໂດຍຂໍ້ມູນລໍາດັບ PacBio.DETs ເຫຼົ່ານີ້ສາມາດປຸງແຕ່ງຕື່ມອີກສໍາລັບການວິເຄາະທີ່ເປັນປະໂຫຍດຕ່າງໆ, ເຊັ່ນ: ການວິເຄາະການຂະຫຍາຍເສັ້ນທາງ KEGG.
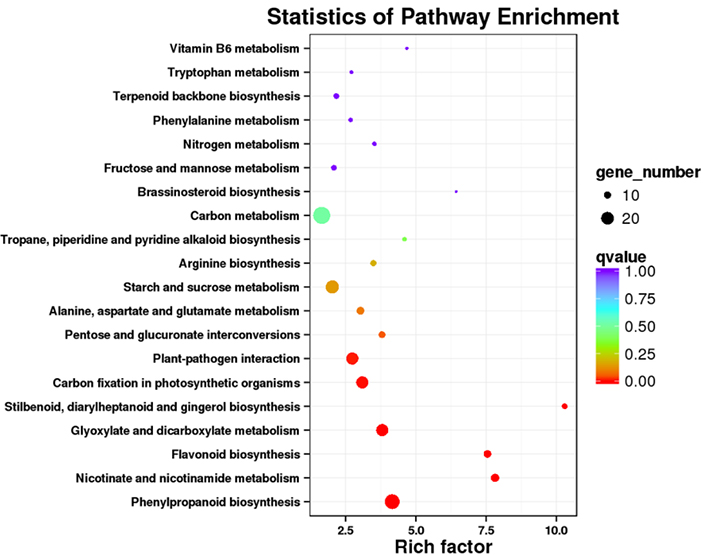
ການເສີມສ້າງເສັ້ນທາງ DET KEGG -Dot plot
ກໍລະນີ BMK
ນະໂຍບາຍດ້ານການພັດທະນາຂອງ transcriptome ລໍາ Populus
ຈັດພີມມາ: ວາລະສານເຕັກໂນໂລຊີຊີວະພາບພືດ, 2019
ຍຸດທະສາດການຈັດລໍາດັບ:
ການເກັບຕົວຢ່າງ:ພາກພື້ນຂອງລໍາຕົ້ນ: ປາຍ, internode ທໍາອິດ (IN1), internode ທີສອງ (IN2), internode ທີສາມ (IN3), internode (IN4) ແລະ internode (IN5) ຈາກ Nanlin895
NGS-ລໍາດັບ:RNA ຂອງ 15 ບຸກຄົນໄດ້ຖືກລວມເຂົ້າເປັນຕົວຢ່າງທາງຊີວະພາບຫນຶ່ງ.ສາມສິ່ງຈໍາລອງທາງຊີວະພາບຂອງແຕ່ລະຈຸດໄດ້ຖືກປຸງແຕ່ງສໍາລັບລໍາດັບ NGS
ລໍາດັບ TGS:ພາກພື້ນຂອງລໍາໄດ້ຖືກແບ່ງອອກເປັນສາມຂົງເຂດ, ເຊັ່ນ: ປາຍ, IN1-IN3 ແລະ IN4-IN5.ແຕ່ລະພາກພື້ນໄດ້ຖືກປຸງແຕ່ງສໍາລັບການຈັດລໍາດັບ PacBio ດ້ວຍສີ່ປະເພດຂອງຫ້ອງສະຫມຸດ: 0-1 kb, 1-2 kb, 2-3 kb ແລະ 3-10 kb.
ຜົນໄດ້ຮັບທີ່ສໍາຄັນ
1.A ຈໍານວນທັງຫມົດຂອງ 87150 transcripts ຄວາມຍາວເຕັມໄດ້ຖືກລະບຸ, ໃນນັ້ນ, 2081 isoforms Novell ແລະ 62058 Novell isoforms spliced ທາງເລືອກໄດ້ຖືກລະບຸ.
2.1187 lncRNA ແລະ 356 genes fusion ໄດ້ຖືກລະບຸ.
3. ຈາກການຂະຫຍາຍຕົວຂັ້ນຕົ້ນໄປສູ່ການເຕີບໂຕຂັ້ນສອງ, 15838 ຂໍ້ຄວາມທີ່ສະແດງຄວາມແຕກຕ່າງຈາກ 995 genes ທີ່ສະແດງອອກແຕກຕ່າງກັນໄດ້ຖືກລະບຸ.ໃນ DEGs ທັງໝົດ, 1216 ແມ່ນປັດໃຈການຖອດຂໍ້ຄວາມ, ເຊິ່ງສ່ວນໃຫຍ່ຍັງບໍ່ທັນໄດ້ລາຍງານເທື່ອ.
4.GO enrichment ການວິເຄາະໄດ້ເປີດເຜີຍຄວາມສໍາຄັນຂອງການແບ່ງຈຸລັງແລະຂະບວນການຫຼຸດຜ່ອນການຜຸພັງໃນການຂະຫຍາຍຕົວປະຖົມແລະມັດທະຍົມ.
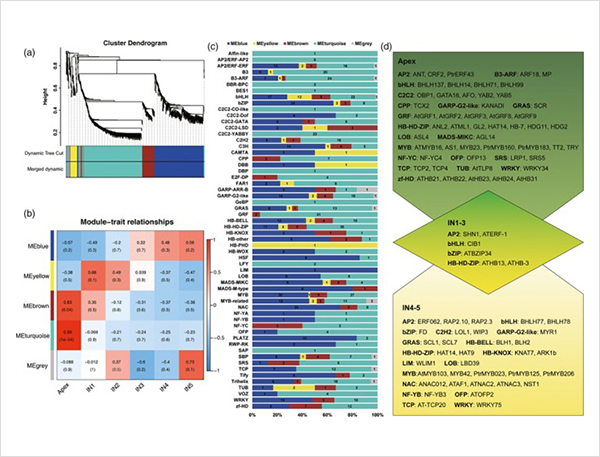
ເຫດການ splicing ທາງເລືອກແລະ isoforms ທີ່ແຕກຕ່າງກັນ
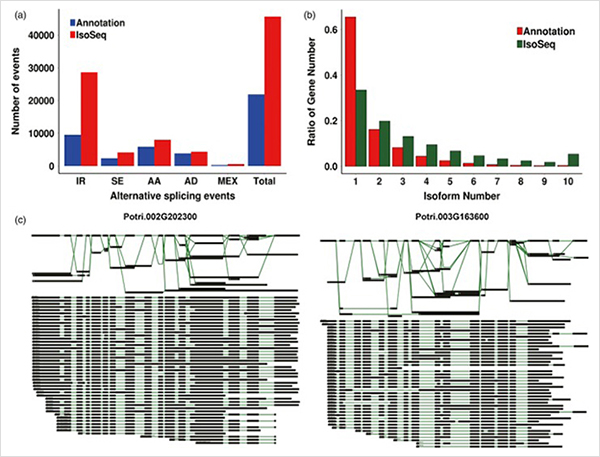
ການວິເຄາະ WGCNA ກ່ຽວກັບປັດໃຈການຖອດຂໍ້ຄວາມ
ອ້າງອິງ
Chao Q, Gao ZF, Zhang D, et al.ນະໂຍບາຍດ້ານການພັດທະນາຂອງ transcriptome ລໍາ Populus.Plant Biotechnol J. 2019;17(1):206-219.doi:10.1111/pbi.12958





