일루미나와 BGI



특징
●플랫폼:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten 및 BGI-DNB-T7
●시퀀싱 모드:PE50, PE100, PE150, PE250
●시퀀싱 전 라이브러리의 품질 관리
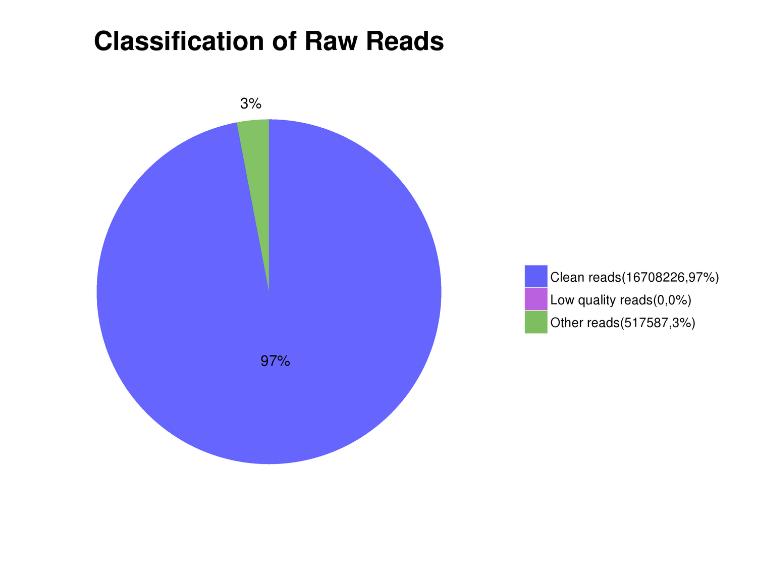
●시퀀싱 데이터 전달 및 QC:Q30 읽기를 역다중화 및 필터링한 후 QC 보고서 및 원시 데이터를 fastq 형식으로 전달합니다.
서비스 장점
●시퀀싱 서비스의 다양성:고객은 레인, 플로우 셀 또는 데이터 양별로 시퀀싱을 선택할 수 있습니다.
●플랫폼의 다양성:DNB 라이브러리를 Illumina 플랫폼으로 전송할 수 있습니다.
●Illumina 시퀀싱 플랫폼에 대한 광범위한 경험:다양한 종을 다루는 수천 개의 비공개 프로젝트가 있습니다.
●시퀀싱 QC 보고서 전달:품질 지표, 데이터 정확성 및 시퀀싱 프로젝트의 전반적인 성능을 활용합니다.
●성숙한 서열분석 과정:짧은 처리 시간으로.
●엄격한 품질 관리: 우리는 일관된 고품질 결과 제공을 보장하기 위해 엄격한 QC 요구 사항을 구현합니다.
샘플 요구사항*
부분 차선 시퀀싱
| 데이터 양(X) | 농도(qPCR/nM) | 용량 |
| X ≤ 50Gb | ≥ 2nM | ≥ 20μl |
| 50Gb ≤ X < 100Gb | ≥ 3nM | ≥ 20μl |
| X ≥ 100GB | ≥ 4nM | ≥ 20μl |
단일 레인(Illumina)
| 플랫폼 | 농도(qPCR/nM) | 용량 |
| HiSeq X Ten | ≥ 2nM | ≥ 20μl |
| NovaSeq 6000 SP | ≥ 1nM | ≥ 25μl |
| NovaSeq 6000 S4 | ≥ 1.5nM | ≥ 25μl |
| NovaSeq X | ≥ 1.5nM | ≥ 25μl |
| BGI-DNBSEQ-T7 | ≥ 1.5nM | ≥ 25μl |
농도와 총량 외에 적절한 피크 패턴도 필요합니다.
귀하의 샘플이 출발 물질 요구 사항을 충족하지 못하는 경우 당사에 문의해 주십시오.
서비스 워크플로
도서관 품질 관리

시퀀싱

데이터 품질 관리

프로젝트 납품
도서관 QC 보고서
시퀀싱, 라이브러리 양 평가 및 단편화 전에 라이브러리 품질에 대한 보고서가 제공됩니다.
시퀀싱 QC 보고서
표 1. 시퀀싱 데이터에 대한 통계
| 샘플 ID | BM키드 | 원시 읽기 | 원시 데이터(bp) | 깨끗한 읽기(%) | 2020년(%) | Q30(%) | GC(%) |
| C_01 | BMK_01 | 22,870,120 | 6,861,036,000 | 96.48 | 99.14 | 94.85 | 36.67 |
| C_02 | BMK_02 | 14,717,867 | 4,415,360,100 | 96.00 | 98.95 | 93.89 | 8.37 |
그림 1. 각 샘플의 읽기에 따른 품질 분포
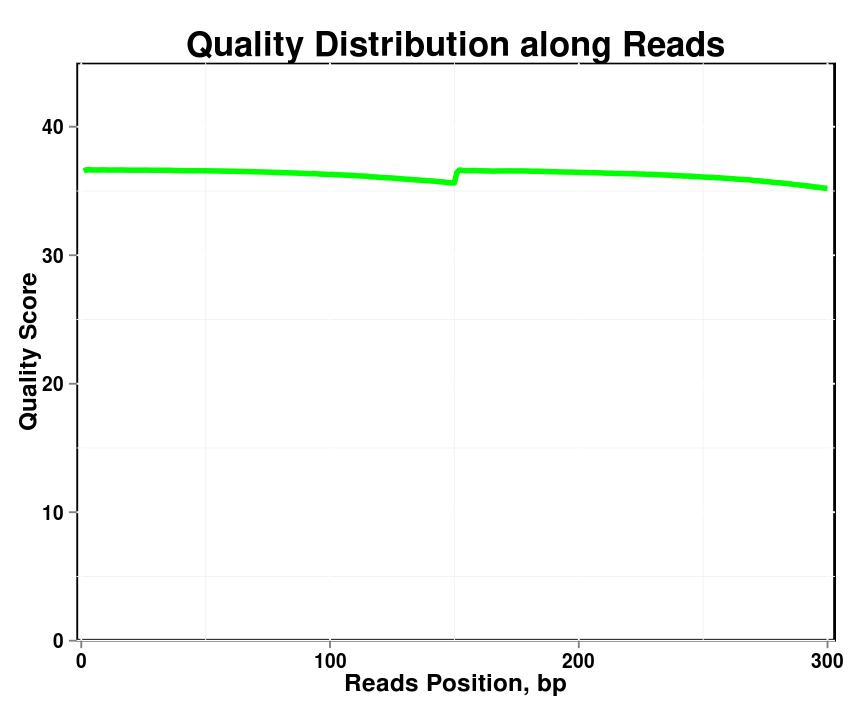
그림 2. 기본 콘텐츠 배포
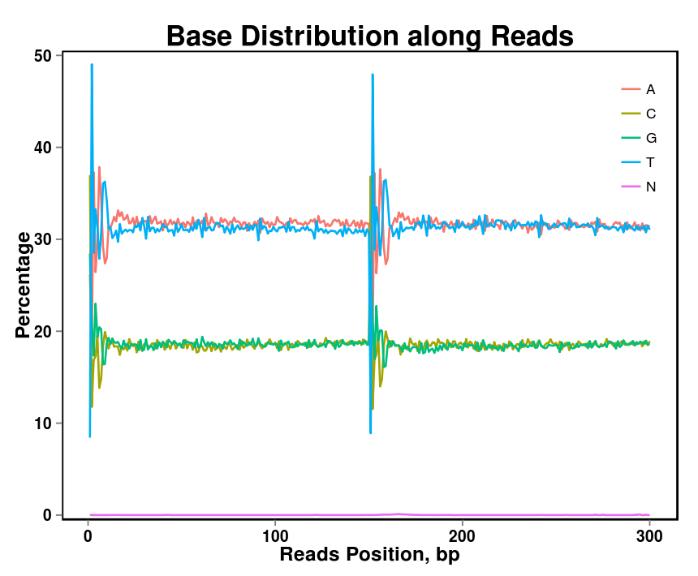
그림 3. 시퀀싱 데이터의 읽기 내용 분포