Illumina e BGI



Caratteristiche
●Piattaforme:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten e BGI-DNB-T7
●Modalità di sequenziamento:PE50, PE100, PE150, PE250
●Controllo di qualità delle librerie prima del sequenziamento
●Sequenziamento della consegna dei dati e QC:consegna del report QC e dei dati grezzi in formato fastq dopo aver demultiplexato e filtrato le letture Q30.
Vantaggi del servizio
●Versatilità dei servizi di sequenziamento:il cliente può scegliere di sequenziare per corsia, cella a flusso o quantità di dati.
●Versatilità delle piattaforme:Le librerie DNB possono essere trasferite su piattaforme Illumina
●Vasta esperienza sulla piattaforma di sequenziamento Illumina:con migliaia di progetti chiusi con varie specie.
●Consegna del rapporto QC del sequenziamento:con metriche di qualità, accuratezza dei dati e prestazioni complessive del progetto di sequenziamento.
●Processo di sequenziamento maturo:con tempi di consegna brevi.
●Controllo qualità rigoroso: implementiamo severi requisiti di controllo qualità per garantire la fornitura di risultati costantemente di alta qualità.
Requisiti del campione*
Sequenziamento parziale delle corsie
| Quantità di dati (X) | Concentrazione (qPCR/nM) | Volume |
| X ≤ 50 GB | ≥ 2 nM | ≥ 20 µl |
| 50 GB ≤ X < 100 GB | ≥ 3 nM | ≥ 20 µl |
| X ≥ 100 GB | ≥ 4 nM | ≥ 20 µl |
Corsia singola (Illumina)
| piattaforma | Concentrazione (qPCR/nM) | Volume |
| HiSeq X Ten | ≥ 2 nM | ≥ 20 µl |
| NovaSeq 6000SP | ≥ 1 nM | ≥ 25 µl |
| NovaSeq 6000 S4 | ≥ 1,5 nM | ≥ 25 µl |
| NovaSeqX | ≥ 1,5 nM | ≥ 25 µl |
| BGI-DNBSEQ-T7 | ≥ 1,5 nM | ≥ 25 µl |
Oltre alla concentrazione e alla quantità totale, è necessario anche un adeguato schema dei picchi.
Vi preghiamo di contattarci se i vostri campioni non soddisfano i requisiti del materiale di partenza.
Flusso di lavoro del servizio
Controllo di qualità della biblioteca

Sequenziamento

Controllo della qualità dei dati

Consegna del progetto
Rapporto QC della libreria
Prima del sequenziamento viene fornito un rapporto sulla qualità della libreria, valutando la quantità e la frammentazione della libreria.
Rapporto di controllo qualità del sequenziamento
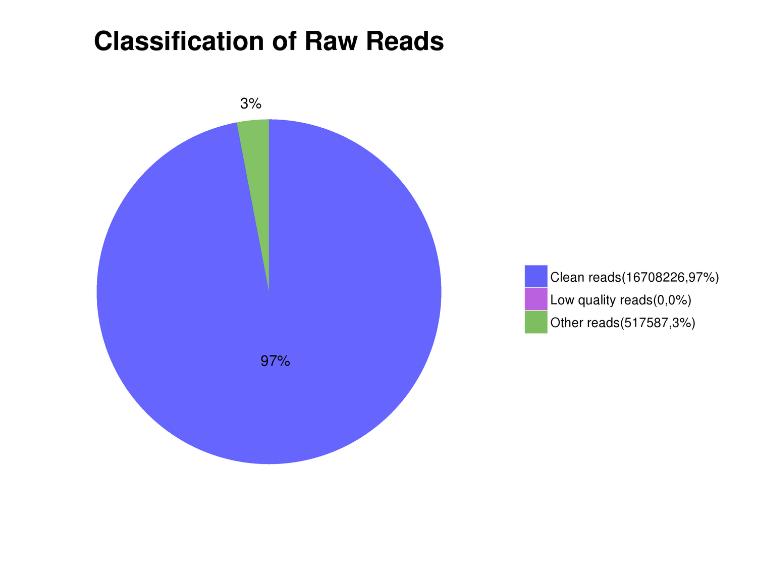
Tabella 1. Statistiche sui dati di sequenziamento.
| ID campione | BMKID | Letture crude | Dati grezzi (bp) | Letture pulite (%) | Q20(%) | Q30(%) | GA(%) |
| C_01 | BMK_01 | 22.870.120 | 6.861.036.000 | 96,48 | 99.14 | 94,85 | 36.67 |
| C_02 | BMK_02 | 14.717.867 | 4.415.360.100 | 96,00 | 98,95 | 93,89 | 37.08 |
Figura 1. Distribuzione della qualità lungo le letture in ciascun campione
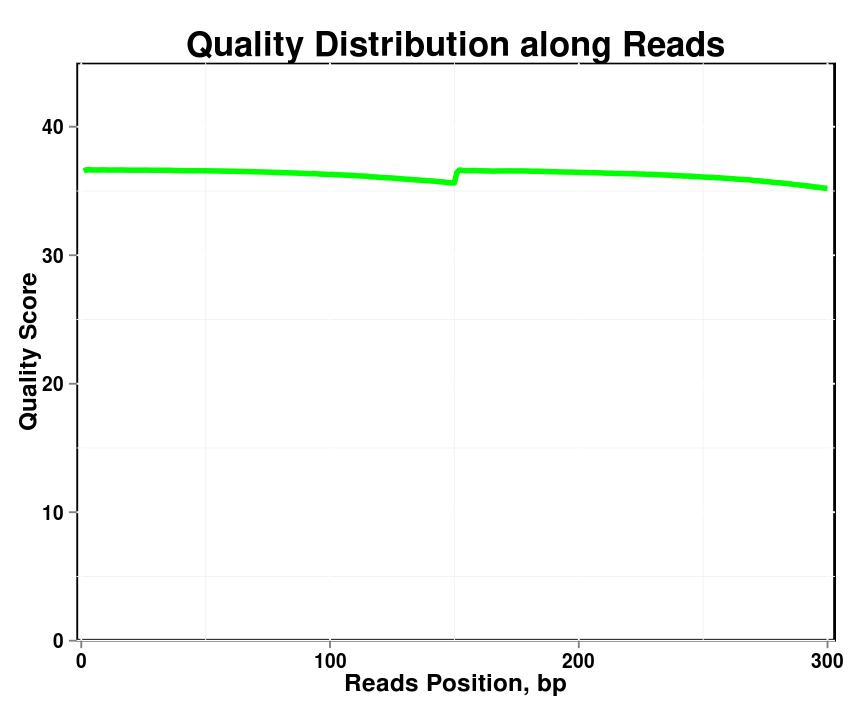
Figura 2. Distribuzione del contenuto di base
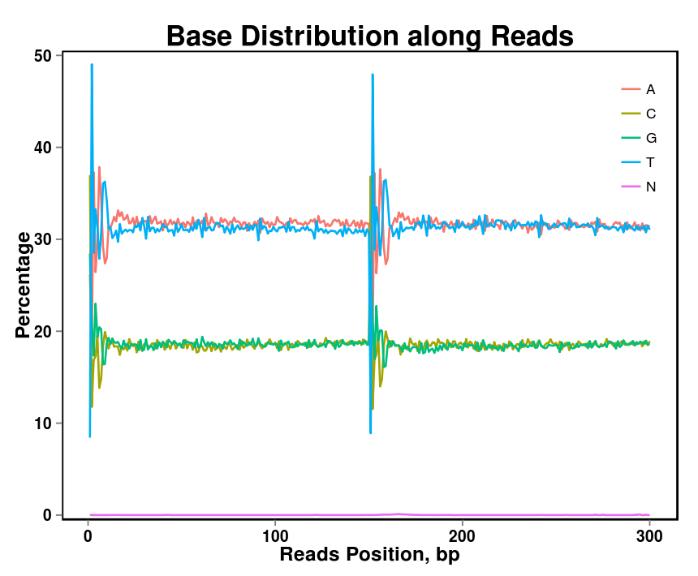
Figura 3. Distribuzione dei contenuti letti nei dati di sequenziamento