

RESECUENCIACIÓN DEL GENOMA COMPLETO

Variantes estructurales en la población china y su impacto en fenotipos, enfermedades y adaptación poblacional.
Nanoporo |PacBio |Resecuenciación del genoma completo |Llamada de variación estructural
En este estudio, Biomarker Technologies proporcionó la secuenciación de Nanopore PromethION.
Reflejos
En este estudio, se reveló un panorama general de variaciones estructurales (SV) en el genoma humano con la ayuda de una secuenciación de lectura larga en la plataforma Nanopore PromethION, que profundiza la comprensión de las SV en fenotipos, enfermedades y evolución.
Diseño experimental
Muestras: leucocitos de sangre periférica de 405 individuos chinos no emparentados (206 hombres y 199 mujeres) con 68 mediciones fenotípicas y clínicas.Entre todos los individuos, las regiones ancestrales de 124 individuos eran provincias del Norte, las de 198 individuos eran del Sur, 53 eran del Suroeste y 30 eran desconocidas.
Estrategia de secuenciación: secuenciación de lectura larga (LRS) del genoma completo con lecturas Nanopore 1D y lecturas PacBio HiFi.
Plataforma de secuenciación: Nanopore PromethION;PacBio Secuela II
Llamada de variación de estructura
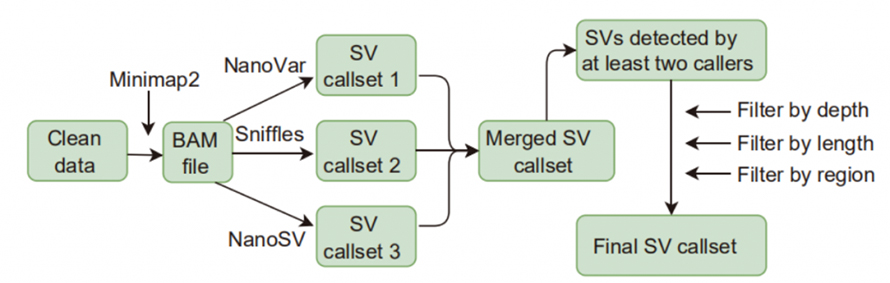
Figura 1. Flujo de trabajo de llamadas y filtrado de SV
Logros principales
Descubrimiento y validación de variaciones de estructuras.
Conjunto de fechas de nanoporos: un total de 20,7 Tb de lecturas limpias generadas en la plataforma de secuenciación PromethION, logrando un promedio de 51 Gb de datos por muestra, aprox.17 veces en profundidad.
Alineación del genoma de referencia (GRCh38): se logró una tasa de mapeo promedio del 94,1 %.La tasa de error media (12,6%) fue similar a la de un estudio de evaluación comparativa anterior (12,6%) (Figura 2b y 2c).
Llamadas de variación de estructura (SV): las llamadas de SV aplicadas en este estudio incluyeron Sniffles, NanoVar y NanoSV.Los SV de alta confianza se definieron como SV identificados por al menos dos personas que llamaron y pasaron filtraciones en profundidad, longitud y región.
En cada muestra se identificó un promedio de 18.489 (entre 15.439 y 22.505) SV de alta confianza.(Figura 2d, 2e y 2f)
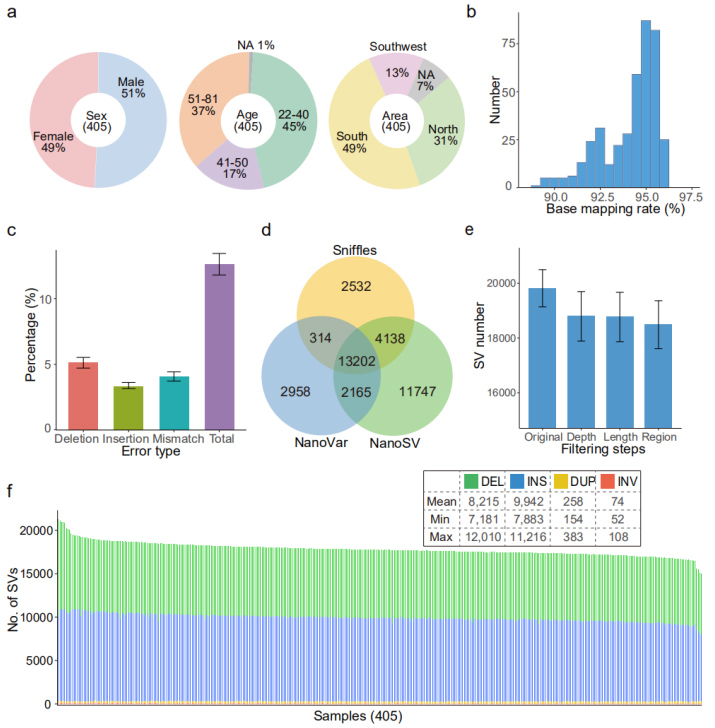
Figura 2. Panorama general de SV identificados por el conjunto de datos de Nanopore
Validación por PacBio: los SV identificados en una muestra (HG002, niño) fueron validados por un conjunto de datos PacBio HiFi.La tasa general de descubrimiento falso (FDR) fue del 3,2 %, lo que ilustra una identificación de SV relativamente confiable mediante lecturas de Nanopore.
SV no redundantes y características genómicas.
SV no redundantes: se obtuvo un conjunto de 132 312 SV no redundantes fusionando SV en todas las muestras, que incluyen 67 405 DEL, 60 182 INS, 3956 DUP y 769 INV.(Figura 3a)
Comparación con conjuntos de datos SV existentes: este conjunto de datos se comparó con el conjunto de datos TGS o NGS publicado.Dentro de los cuatro conjuntos de datos comparados, LRS15, que también es el único conjunto de datos de la plataforma de secuenciación de lectura larga (PacBio), compartió las mayores superposiciones con este conjunto de datos.Además, el 53,3% (70.471) de los VS en este conjunto de datos se informaron por primera vez.Al analizar cada tipo de SV, la cantidad de INS recuperados con un conjunto de datos de secuenciación de lectura larga fue mucho mayor que el resto de los de lectura corta, lo que indica que la secuenciación de lectura larga es particularmente eficiente en la detección de INS.(Figura 3b y 3c)
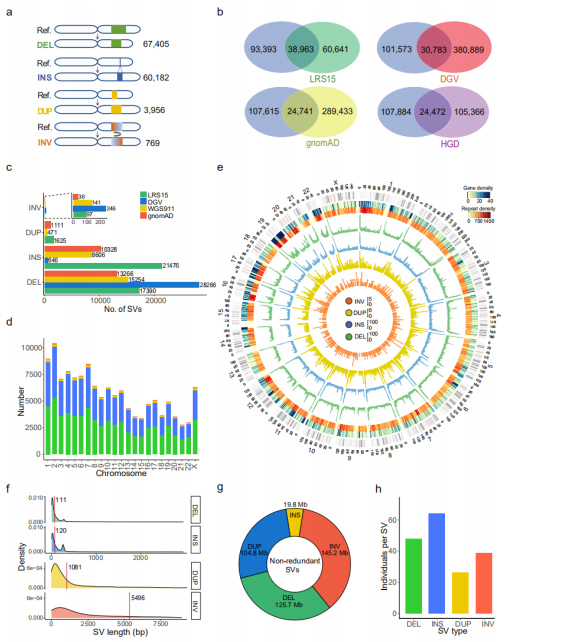
Figura 3. Propiedades de los SV no redundantes para cada tipo de SV
Características genómicas: se encontró que el número de VS estaba significativamente correlacionado con la longitud del cromosoma.La distribución de genes, repeticiones, DEL (verde), INS (azul), DUP (amarillo) e INV (naranja) se mostraron en un diagrama de Circos, donde se observó un aumento general en SV al final de los brazos de los cromosomas.(Figura 3d y 3e)
Longitud de los SV: Se encontró que las longitudes de los INS y DEL eran significativamente más cortas que las de los DUP e INV, que coincidían con las identificadas por el conjunto de datos de PacBio HiFi.La longitud de todos los SV identificados sumó 395,6 Mb, que ocuparon el 13,2% de todo el genoma humano.Los SV afectaron a 23,0 Mb (aproximadamente 0,8%) del genoma por individuo en promedio.(Figura 3f y 3g)
Impactos funcionales, fenotípicos y clínicos de los SV
SV de pérdida de función prevista (pLoF): los SV de pLoF se definieron como SV que interactuaban con CDS, donde se eliminaron los nucleótidos codificantes o se alteraron los ORF.Se anotaron un total de 1.929 pLoF SV que afectan a CDS de 1.681 genes.Dentro de ellos, 38 genes destacaron la "unión al receptor de inmunoglobulinas" en el análisis de enriquecimiento de GO.Estos pLoF SV fueron anotados adicionalmente por GWAS, OMIM y COSMIC, respectivamente.(Figura 4a y 4b)
SV fenotípica y clínicamente relevantes: Se demostró que varios SV en el conjunto de datos de nanoporos son fenotípica y clínicamente relevantes.Se identificó en tres individuos un raro DEL heterocigoto de 19,3 kb, que se sabe que causa alfa-talasemia, que disfuncionaba los genes de las subunidades alfa 1 y 2 de hemoglobina (HBA1 y HBA2).En otro individuo se identificó otro DEL de 27,4 kb en el gen que codifica la subunidad beta de hemoglobina (HBB).Se sabía que este SV causaba hemoglobinopatías graves.(Figura 4c)
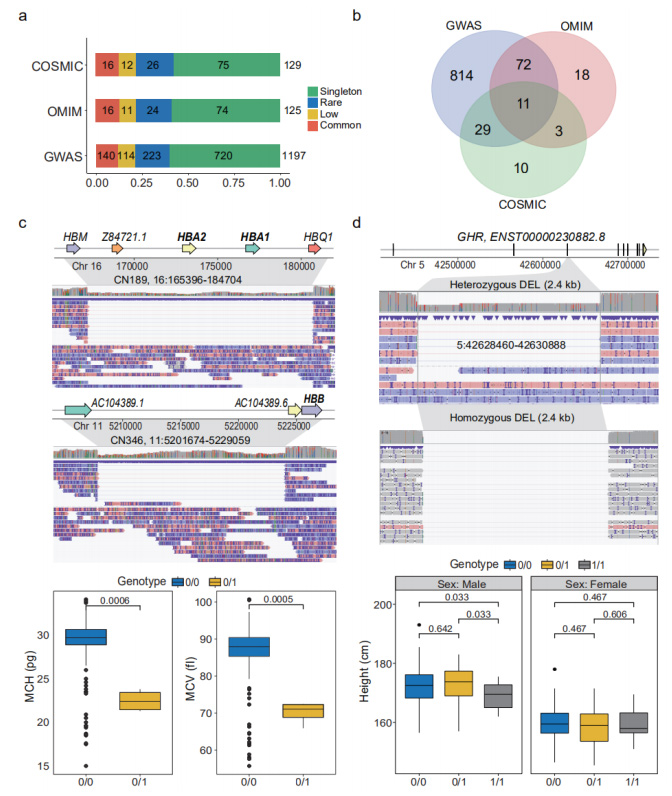
Figura 4. pLoF SV asociados con fenotipos y enfermedades
Se observó un DEL común de 2,4 kb en 35 portadores homocigotos y 67 portadores heterocigotos, que cubre la región completa del tercer exón del receptor de homona de crecimiento (GHR).Los portadores homocigotos fueron significativamente más bajos que los heterocigotos (p=0,033).(Figura 4d)
Además, estos SV se procesaron para estudios evolutivos de la población entre dos grupos regionales: el norte y el sur de China.Se encontraron SV significativamente diferenciales distribuidos en Chr 1, 2, 3, 6,10,12,14 y 19, dentro de los cuales, los superiores estaban asociados con regiones de inmunidad, como IGH, MHC, etc. Es razonable especular que La diferenciación en estos SV puede deberse a la deriva genética y la exposición a largo plazo a diversos entornos para subpoblaciones en China.
Referencia
Wu, Zhikun y otros."Variantes estructurales en la población china y su impacto en los fenotipos, las enfermedades y la adaptación de la población".bioRxiv(2021).
Noticias y destacados tiene como objetivo compartir los últimos casos exitosos con Biomarker Technologies, capturando logros científicos novedosos, así como técnicas destacadas aplicadas durante el estudio.
Hora de publicación: 06-ene-2022