

Análisis segregante masivo







Ventajas del servicio
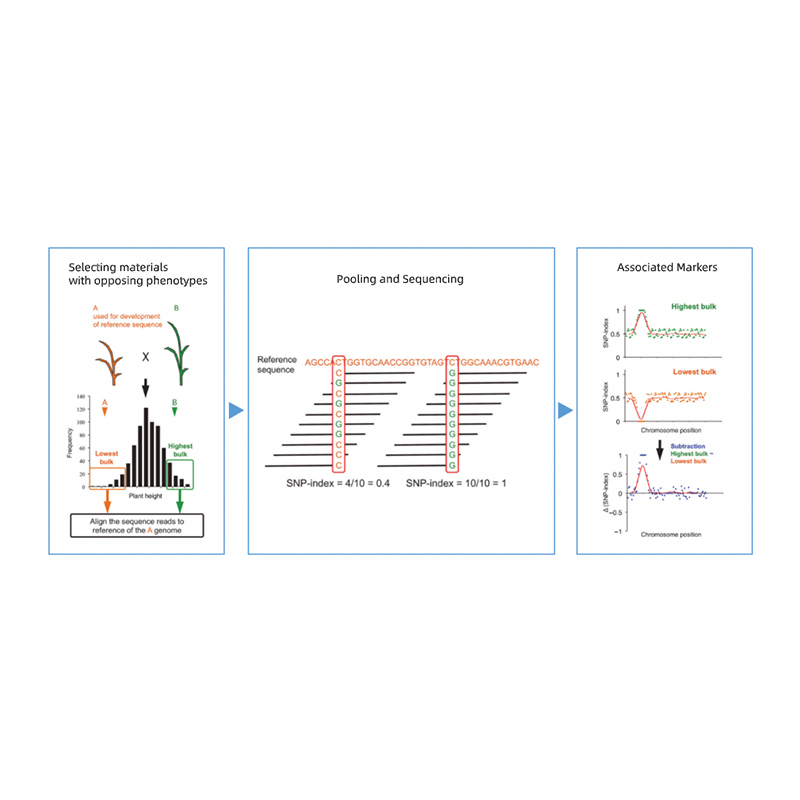
Takagi et al., The Plant Journal, 2013.
● Localización precisa: mezcla de grupos de 30+30 a 200+200 personas para minimizar el ruido de fondo;Predicción de regiones candidatas basadas en mutantes no sinónimos.
● Análisis integral: anotación detallada de la función del gen candidato, incluidos NR, SwissProt, GO, KEGG, COG, KOG, etc.
● Tiempo de respuesta más rápido: localización genética rápida en 45 días hábiles.
● Amplia experiencia: BMK ha contribuido en la localización de miles de rasgos, abarcando diversas especies como cultivos, productos acuáticos, bosques, flores, frutas, etc.
Especificaciones de servicio
Población:
Segregación de la progenie de padres con fenotipos opuestos.
por ejemplo, progenie F2, retrocruzamiento (BC), línea endogámica recombinante (RIL)
piscina de mezcla
Para rasgos cualitativos: 30 a 50 individuos (mínimo 20)/a granel
Para tratis cuantitativos: entre el 5% y el 10% de los individuos superiores con cualquiera de los fenotipos extremos en toda la población (mínimo 30+30).
Profundidad de secuenciación recomendada
Al menos 20X/padre y 1X/descendiente individual (por ejemplo, para un grupo de mezcla de descendientes de 30+30 individuos, la profundidad de secuenciación será 30X por lote)
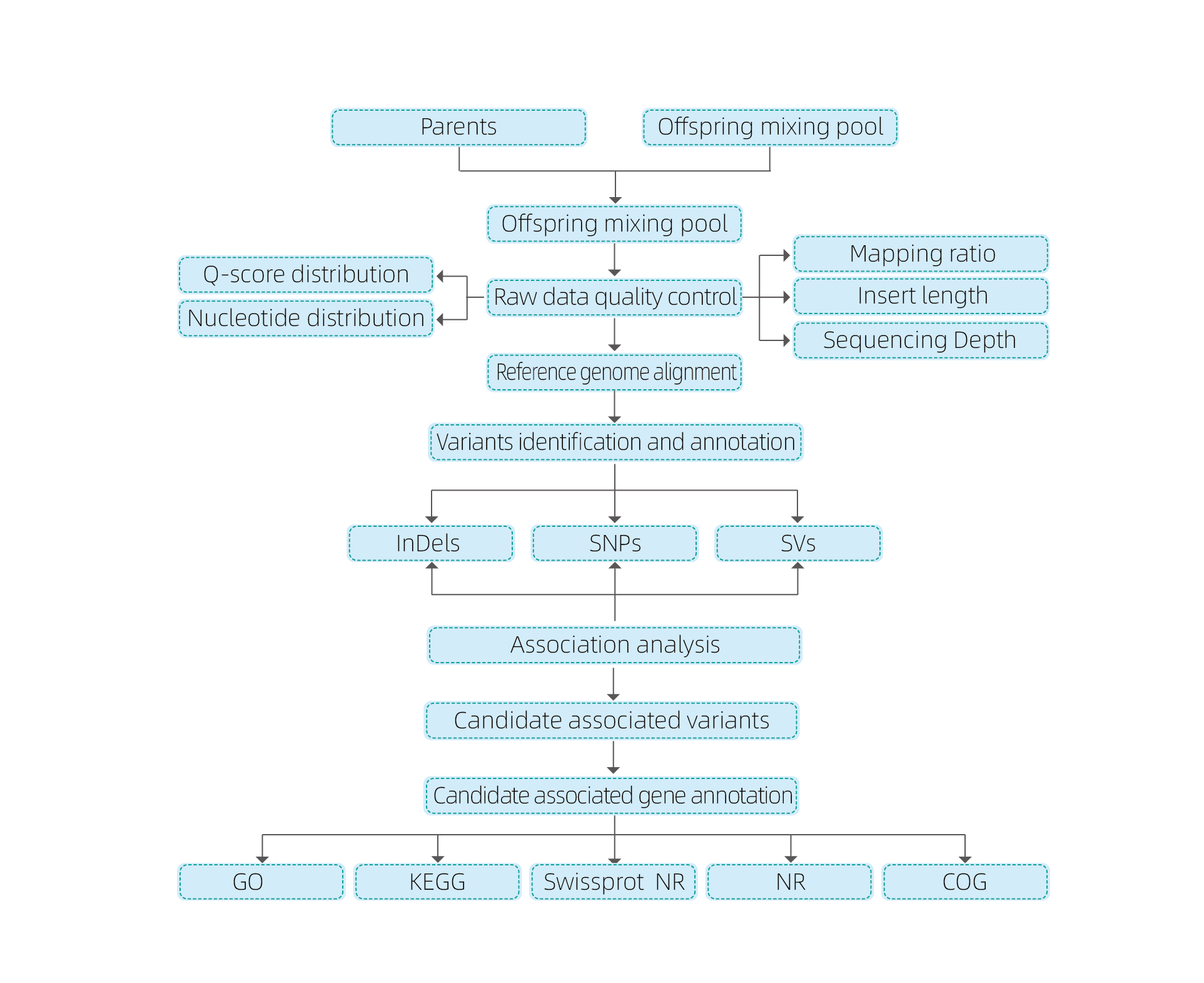
Análisis bioinformáticos.
● Resecuenciación del genoma completo
● Procesamiento de datos
● Llamadas SNP/Indel
● Selección de regiones candidatas
● Anotación de función del gen candidato
Requisitos de muestra y entrega
Requisitos de muestra:
Nucleótidos:
| muestra de ADNg | Muestra de tejido |
| Concentración: ≥30 ng/μl | Plantas: 1-2 g |
| Cantidad: ≥2 μg (Volumen ≥15 μl) | Animales: 0,5-1 g |
| Pureza: OD260/280= 1,6-2,5 | Sangre total: 1,5 ml |
Flujo de trabajo del servicio

Diseño de experimentos
Entrega de muestra
extracción de ARN
construcción de biblioteca

Secuenciación

Análisis de los datos
Servicios postventa
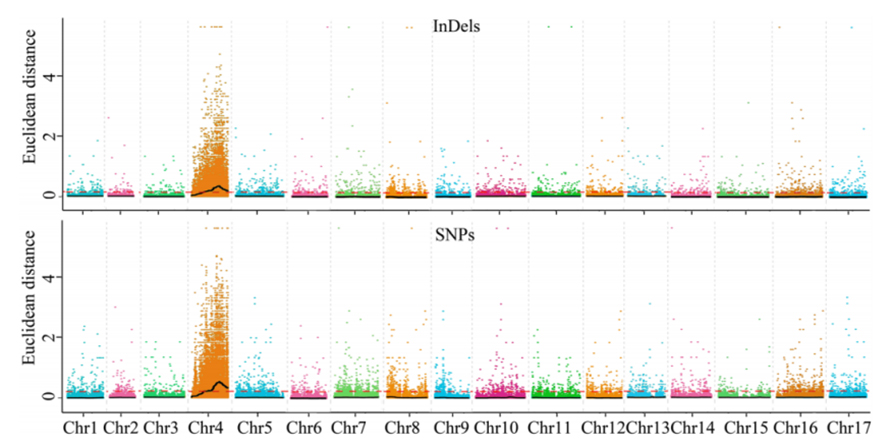
1.Análisis de asociación basado en la distancia euclidiana (ED) para identificar la región candidata.En la siguiente figura
Eje X: número de cromosomas;Cada punto representa un valor de ED de un SNP.La línea negra corresponde al valor ED ajustado.Un valor de DE más alto indica una asociación más significativa entre el sitio y el fenotipo.La línea discontinua roja representa el umbral de asociación significativa.
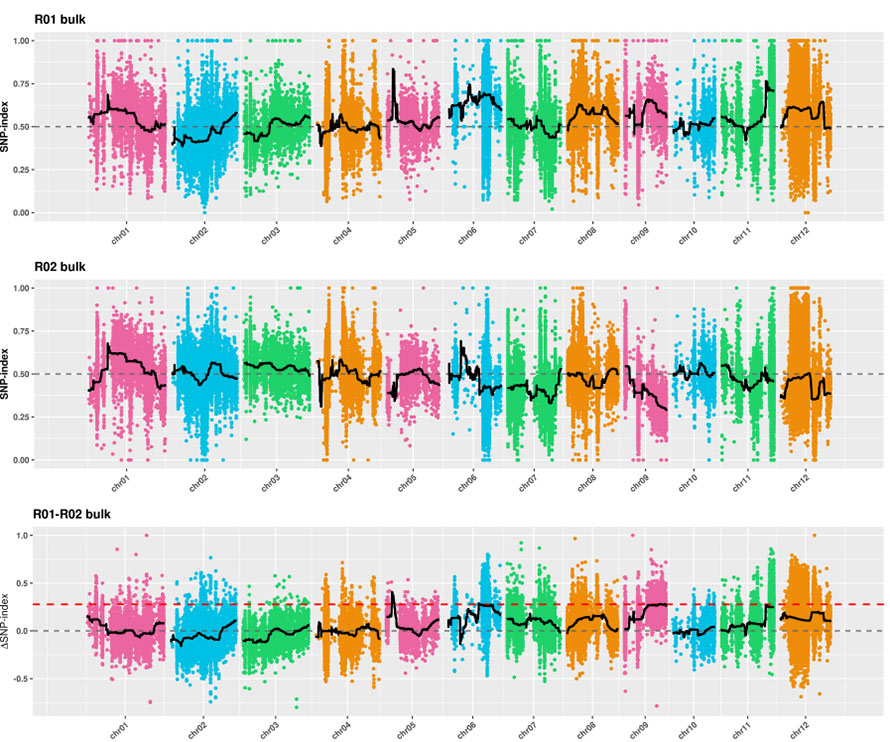
2.Análisis de asociación basado en ningún índice SNP
Eje X: número de cromosomas;Cada punto representa el valor del índice SNP.La línea negra representa el valor del índice SNP ajustado.Cuanto mayor sea el valor, más significativa será la asociación.
Caso BMK
El locus Fnl7.1 del rasgo cuantitativo de efecto principal codifica una proteína abundante en la embriogénesis tardía asociada con la longitud del cuello del fruto en pepino
Publicado: Revista de biotecnología vegetal, 2020
Estrategia de secuenciación:
Padres (Jin5-508, YN): Resecuenciación del genoma completo para 34× y 20×.
Conjuntos de ADN (50 de cuello largo y 50 de cuello corto): Resecuenciación para 61× y 52×
Resultados clave
En este estudio, la población segregante (F2 y F2:3) se generó cruzando la línea de pepino de cuello largo Jin5-508 y la de cuello corto YN.Se construyeron dos grupos de ADN con 50 individuos de cuello extremadamente largo y 50 individuos de cuello extremadamente corto.El QTL de efecto principal se identificó en Chr07 mediante análisis BSA y mapeo de QTL tradicional.La región candidata se redujo aún más mediante mapeo fino, cuantificación de la expresión genética y experimentos transgénicos, que revelaron un gen clave en el control de la longitud del cuello, CsFnl7.1.Además, se encontró que el polimorfismo en la región promotora CsFnl7.1 estaba asociado con la expresión correspondiente.Un análisis filogenético adicional sugirió que es muy probable que el locus Fnl7.1 se origine en la India.
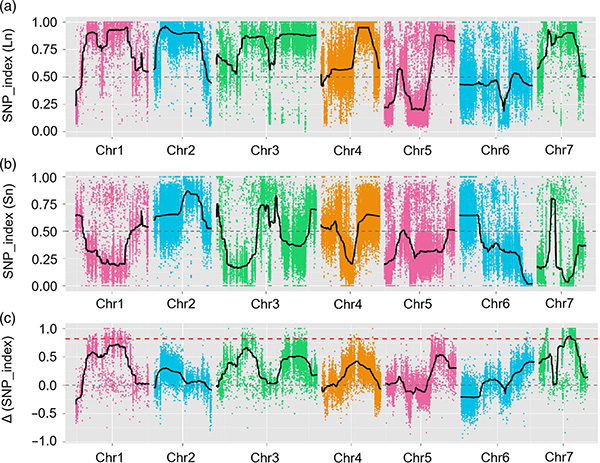 Mapeo de QTL en análisis BSA para identificar la región candidata asociada con la longitud del cuello del pepino | 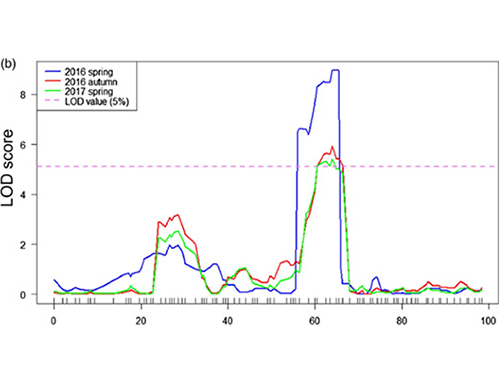 Perfiles LOD de QTL hasta el cuello de pepino identificados en Chr07 |
Xu, X., et al."El locus Fnl7.1 del rasgo cuantitativo de efecto principal codifica una proteína abundante en la embriogénesis tardía asociada con la longitud del cuello del fruto en el pepino".Revista de biotecnología vegetal 18.7 (2020).





