

RESEQUENZIERUNG DES GESAMTEN GENOMS

Strukturvarianten in der chinesischen Bevölkerung und ihre Auswirkungen auf Phänotypen, Krankheiten und Populationsanpassung
Nanopore |PacBio |Neusequenzierung des gesamten Genoms |Strukturvariationsaufruf
In dieser Studie wurde die Nanopore-PromethION-Sequenzierung von Biomarker Technologies bereitgestellt.
Höhepunkte
In dieser Studie wurde mithilfe der Long-Read-Sequenzierung auf der Nanopore PromethION-Plattform eine Gesamtlandschaft struktureller Variationen (SVs) im menschlichen Genom aufgedeckt, die das Verständnis von SVs in Phänotypen, Krankheiten und Evolution vertieft.
Experimentelles Design
Proben: Leukozyten des peripheren Blutes von 405 nicht verwandten chinesischen Individuen (206 Männer und 199 Frauen) mit 68 phänotypischen und klinischen Messungen.Von allen Individuen waren die Herkunftsregionen von 124 Individuen Provinzen im Norden, die von 198 Individuen lagen im Süden, 53 lagen im Südwesten und 30 waren nicht bekannt.
Sequenzierungsstrategie: Long-Read-Sequenzierung des gesamten Genoms (LRS) mit Nanopore 1D-Reads und PacBio HiFi-Reads.
Sequenzierungsplattform: Nanopore PromethION;PacBio Fortsetzung II
Aufruf von Strukturvariationen
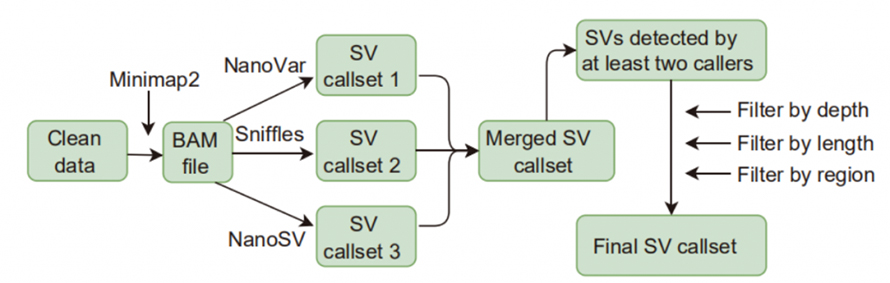
Abbildung 1. Workflow des SV-Aufrufs und -Filters
Haupterfolge
Entdeckung und Validierung von Strukturvariationen
Nanopore-Datensatz: Insgesamt wurden auf der PromethION-Sequenzierungsplattform 20,7 TB saubere Lesevorgänge generiert, wodurch durchschnittlich 51 GB Daten pro Probe erreicht wurden, ca.17-fach tief.
Referenzgenom-Alignment (GRCh38): Es wurde eine durchschnittliche Kartierungsrate von 94,1 % erreicht.Die mittlere Fehlerquote (12,6 %) war ähnlich wie bei einer früheren Benchmarking-Studie (12,6 %) (Abbildung 2b und 2c).
Strukturvariationsaufruf (SV): Zu den in dieser Studie verwendeten SV-Aufrufern gehörten Sniffles, NanoVar und NanoSV.SVs mit hoher Zuverlässigkeit wurden als SVs definiert, die von mindestens zwei Anrufern identifiziert wurden und die Filterung nach Tiefe, Länge und Region bestanden haben.
In jeder Probe wurden durchschnittlich 18.489 (im Bereich von 15.439 bis 22.505) SVs mit hoher Zuverlässigkeit identifiziert.(Abbildung 2d, 2e und 2f)
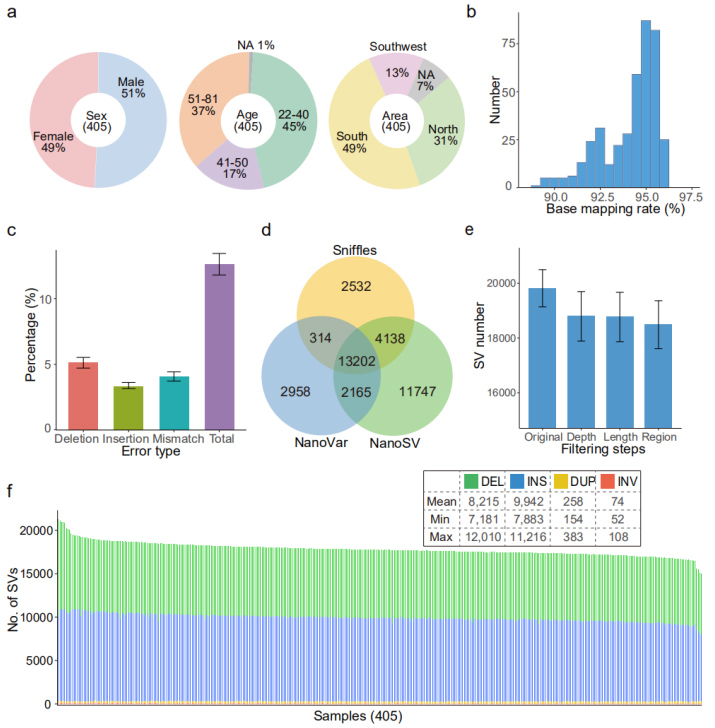
Abbildung 2. Gesamtlandschaft der durch den Nanopore-Datensatz identifizierten SVs
Validierung durch PacBio: In einer Probe (HG002, Kind) identifizierte SVs wurden durch einen PacBio HiFi-Datensatz validiert.Die Gesamtrate falscher Entdeckungen (FDR) betrug 3,2 %, was eine relativ zuverlässige SV-Identifizierung durch Nanopore-Reads verdeutlicht.
Nicht-redundante SVs und genomische Merkmale
Nicht-redundante SVs: Durch Zusammenführen der SVs in allen Stichproben wurde ein Satz von 132.312 nicht-redundanten SVs erhalten, der 67.405 DELs, 60.182 INSs, 3.956 DUPs und 769 INVs umfasst.(Abbildung 3a)
Vergleich mit vorhandenen SV-Datensätzen: Dieser Datensatz wurde mit veröffentlichten TGS- oder NGS-Datensätzen verglichen.Innerhalb der vier verglichenen Datensätze wies LRS15, der auch der einzige Datensatz der Long-Read-Sequenzierungsplattform (PacBio) ist, die größten Überschneidungen mit diesem Datensatz auf.Darüber hinaus wurden 53,3 % (70.471) der SVs in diesem Datensatz zum ersten Mal gemeldet.Bei der Untersuchung jedes SV-Typs war die Anzahl der wiederhergestellten INSs mit Long-Read-Sequenzierungsdatensätzen viel größer als die der übrigen Short-Read-Datensätze, was darauf hindeutet, dass Long-Read-Sequenzierung bei der INSs-Erkennung besonders effizient ist.(Abbildung 3b und 3c)
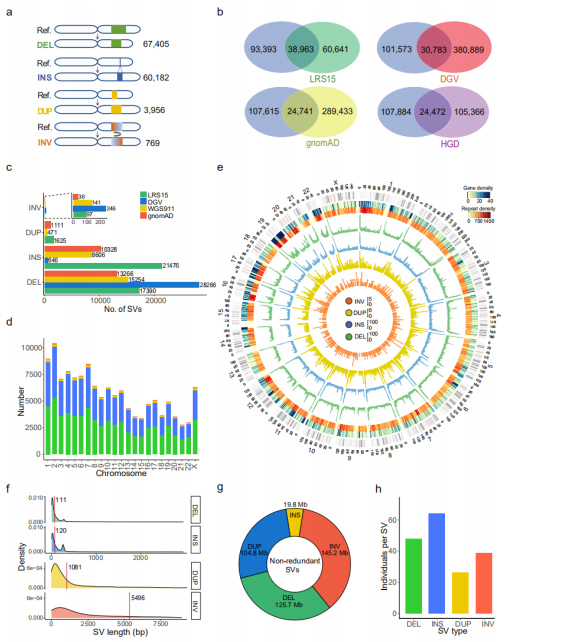
Abbildung 3. Eigenschaften nicht redundanter SVs für jeden SV-Typ
Genomische Merkmale: Es wurde festgestellt, dass die Anzahl der SVs signifikant mit der Chromosomenlänge korreliert.Die Verteilung der Gene, Wiederholungen, DELs (grün), INS (blau), DUP (gelb) und INV (orange) wurden in einem Circos-Diagramm angezeigt, wobei ein allgemeiner Anstieg der SV am Ende der Chromosomenarme beobachtet wurde.(Abbildung 3d und 3e)
Länge der SVs: Es wurde festgestellt, dass die Längen der INSs und DELs deutlich kürzer sind als die der DUPs und INVs, was mit den im PacBio HiFi-Datensatz identifizierten Längen übereinstimmt.Die Länge aller identifizierten SVs belief sich auf 395,6 MB, was 13,2 % des gesamten menschlichen Genoms einnahm.SVs betrafen durchschnittlich 23,0 MB (ca. 0,8 %) des Genoms pro Person.(Abbildung 3f und 3g)
Funktionelle, phänotypische und klinische Auswirkungen von SVs
Vorhergesagter Funktionsverlust (pLoF) SVs: pLoF SVs wurden als SVs definiert, die mit CDS interagierten, wobei kodierende Nukleotide gelöscht oder ORFs verändert wurden.Insgesamt wurden 1.929 pLoF-SVs, die CDS von 1.681 Genen beeinflussen, annotiert.Darunter wiesen 38 Gene in der GO-Anreicherungsanalyse auf „Immunglobulinrezeptorbindung“ hin.Diese pLoF-SVs wurden von GWAS, OMIM bzw. COSMIC weiter kommentiert.(Abbildung 4a und 4b)
Phänotypisch und klinisch relevante SVs: Es wurde gezeigt, dass eine Reihe von SV im Nanoporen-Datensatz phänotypisch und klinisch relevant sind.Ein seltener heterozygoter DEL von 19,3 kb, der bekanntermaßen Alpha-Thalassämie verursacht, wurde bei drei Personen identifiziert, bei denen die Funktion der Gene der Hämoglobin-Untereinheiten Alpha 1 und 2 (HBA1 und HBA2) gestört war.Ein weiterer DEL von 27,4 kb auf dem Gen, das die Hämoglobin-Untereinheit Beta (HBB) kodiert, wurde bei einer anderen Person identifiziert.Es war bekannt, dass dieser SV schwere Hämoglobinopathien verursacht.(Abbildung 4c)
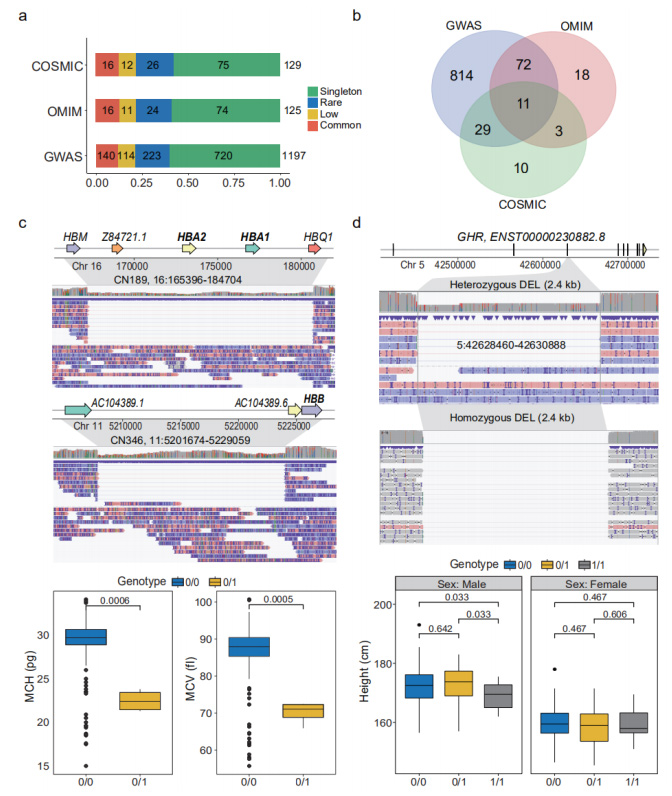
Abbildung 4. pLoF-SVs im Zusammenhang mit Phänotypen und Krankheiten
Bei 35 homozygoten und 67 heterozygoten Trägern wurde ein gemeinsamer DEL von 2,4 kb beobachtet, der die gesamte Region des 3. Exons des Growth Homone Receptor (GHR) abdeckt.Die homozygoten Träger waren deutlich kürzer als die heterozygoten (p=0,033).(Abbildung 4d)
Darüber hinaus wurden diese SVs für Populationsentwicklungsstudien zwischen zwei regionalen Gruppen verarbeitet: Nord- und Südchina.Es wurden deutlich unterschiedliche SVs gefunden, die auf Chr 1, 2, 3, 6, 10, 12, 14 und 19 verteilt waren, wobei die obersten SVs mit Immunregionen wie IGH, MHC usw. assoziiert waren. Es ist vernünftig zu spekulieren, dass die Die Differenzierung dieser SVs kann auf genetische Drift und die langfristige Exposition gegenüber unterschiedlichen Umgebungen für Teilpopulationen in China zurückzuführen sein.
Referenz
Wu, Zhikun et al.„Strukturelle Varianten in der chinesischen Bevölkerung und ihre Auswirkungen auf Phänotypen, Krankheiten und Populationsanpassung.“bioRxiv(2021).
Neuigkeiten und Highlights Ziel ist es, die neuesten erfolgreichen Fälle mit Biomarker-Technologien zu teilen und neue wissenschaftliche Errungenschaften sowie herausragende Techniken, die während der Studie angewendet wurden, zu erfassen.
Zeitpunkt der Veröffentlichung: 06.01.2022