Illumina und BGI



Merkmale
●Plattformen:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten und BGI-DNB-T7
●Sequenzierungsmodi:PE50, PE100, PE150, PE250
●Qualitätskontrolle von Bibliotheken vor der Sequenzierung
●Lieferung der Sequenzierungsdaten und Qualitätskontrolle:Bereitstellung des QC-Berichts und der Rohdaten im FastQ-Format nach Demultiplexierung und Filterung der Q30-Lesevorgänge.
Servicevorteile
●Vielseitigkeit der Sequenzierungsdienste:Der Kunde kann die Reihenfolge nach Spur, Fließzelle oder Datenmenge wählen.
●Vielseitigkeit der Plattformen:DNB-Bibliotheken können auf Illumina-Plattformen übertragen werden
●Umfangreiche Erfahrung mit der Illumina-Sequenzierungsplattform:mit Tausenden abgeschlossenen Projekten mit verschiedenen Arten.
●Lieferung des Sequenzierungs-QC-Berichts:mit Qualitätsmetriken, Datengenauigkeit und Gesamtleistung des Sequenzierungsprojekts.
●Reifer Sequenzierungsprozess:mit kurzer Bearbeitungszeit.
●Strenge Qualitätskontrolle: Wir setzen strenge QC-Anforderungen um, um die Lieferung gleichbleibend hochwertiger Ergebnisse zu gewährleisten.
Probenanforderungen*
Teilweise Spursequenzierung
| Datenmenge (X) | Konzentration (qPCR/nM) | Volumen |
| X ≤ 50 GB | ≥ 2 nM | ≥ 20 μl |
| 50 GB ≤ X < 100 GB | ≥ 3 nM | ≥ 20 μl |
| X ≥ 100 GB | ≥ 4 nM | ≥ 20 μl |
Einspurig (Illumina)
| Plattform | Konzentration (qPCR/nM) | Volumen |
| HiSeq X Ten | ≥ 2 nM | ≥ 20 μl |
| NovaSeq 6000 SP | ≥ 1 nM | ≥ 25 μl |
| NovaSeq 6000 S4 | ≥ 1,5 nM | ≥ 25 μl |
| NovaSeq X | ≥ 1,5 nM | ≥ 25 μl |
| BGI-DNBSEQ-T7 | ≥ 1,5 nM | ≥ 25 μl |
Neben Konzentration und Gesamtmenge ist auch ein passendes Peakmuster erforderlich.
Bitte wenden Sie sich an uns, wenn Ihre Proben nicht den Anforderungen an das Ausgangsmaterial entsprechen.
Service-Workflow
Qualitätskontrolle der Bibliothek

Sequenzierung

Datenqualitätskontrolle

Projektabwicklung
QC-Bericht der Bibliothek
Vor der Sequenzierung wird ein Bericht über die Qualität der Bibliothek erstellt, in dem die Bibliotheksmenge und die Fragmentierung beurteilt werden.
Sequenzierungs-QC-Bericht
Tabelle 1. Statistiken zu Sequenzierungsdaten.
| Proben-ID | BMKID | Rohe Lesevorgänge | Rohdaten (bp) | Saubere Lesevorgänge (%) | Q20(%) | Q30(%) | GC(%) |
| C_01 | BMK_01 | 22.870.120 | 6.861.036.000 | 96,48 | 99,14 | 94,85 | 36,67 |
| C_02 | BMK_02 | 14.717.867 | 4.415.360.100 | 96,00 | 98,95 | 93,89 | 37.08 |
Abbildung 1. Qualitätsverteilung entlang der Lesevorgänge in jeder Stichprobe
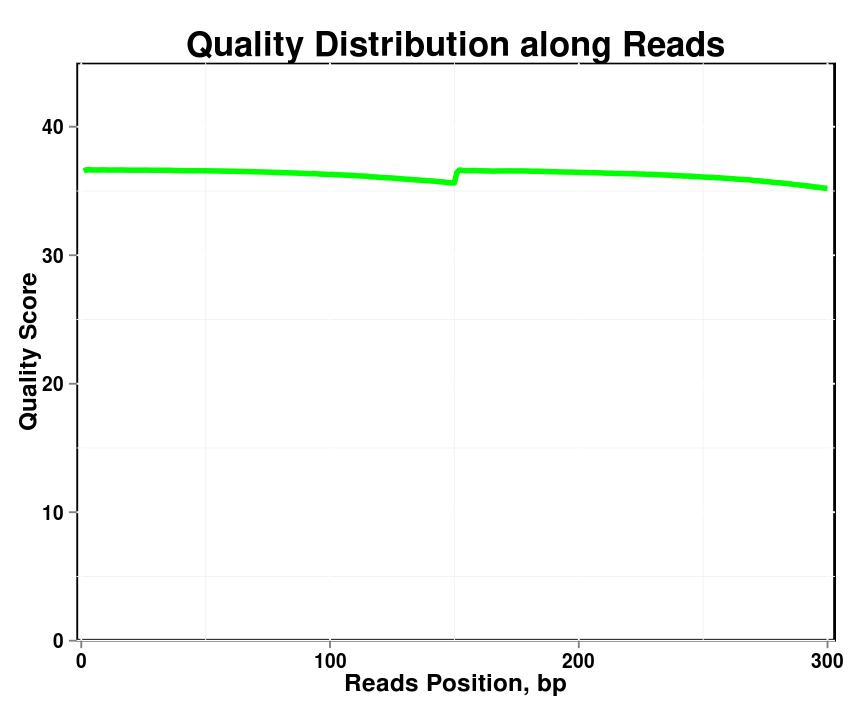
Abbildung 2. Basisinhaltsverteilung
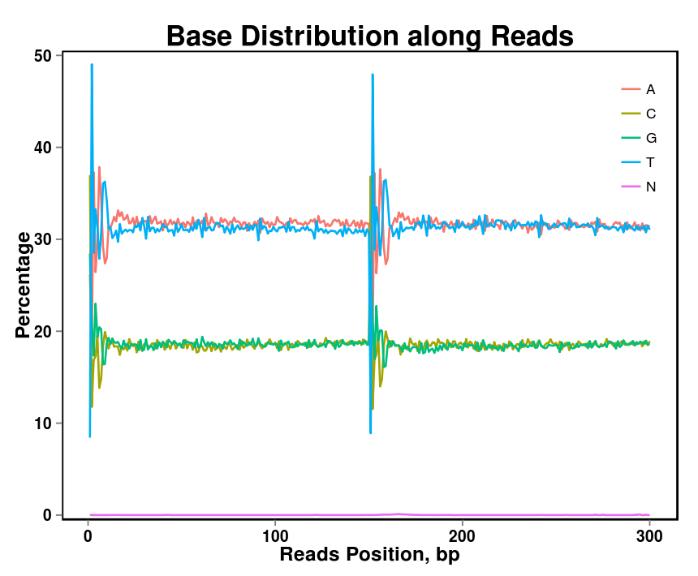
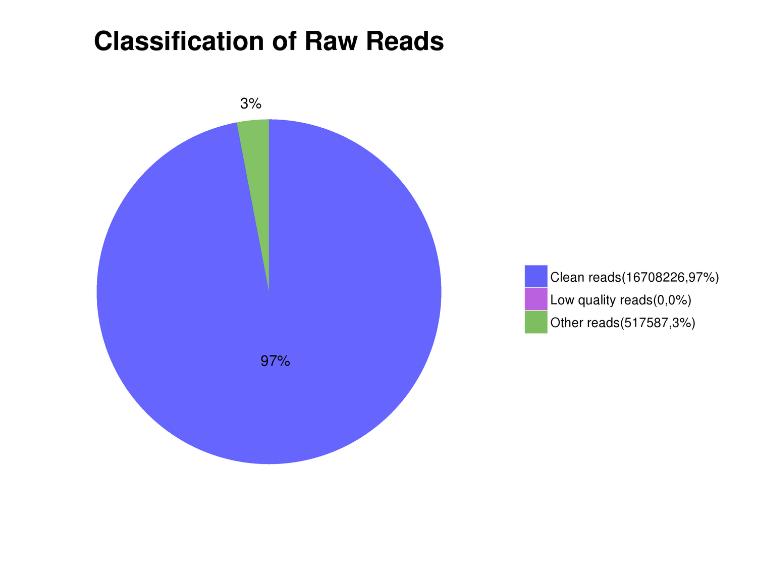
Abbildung 3. Verteilung der gelesenen Inhalte in Sequenzierungsdaten