

METAGENOMIKY

Kompletní, uzavřené bakteriální genomy z mikrobiomů pomocí sekvenování nanoporů
Sekvenování nanoporů |Metagenomika |MAG |Cirkularizace bakteriálního genomu |Střevní mikroflóra
Zvýraznění
1.V této studii byla představena nová metoda pro extrakci dlouhých fragmentů DNA, která dosáhla extrakce mikrogramů čisté, HMW DNA vhodné pro dlouhé sekvenování z 300 mg stolice
2. V této studii byl představen montážní pracovní postup, Soustruh, kde byly MAG sestaveny dlouhým čtením a opraveny krátkým čtením.
3. Soustruh byl hodnocen simulovanou směsí.7 z 12 bakterií bylo úspěšně sestaveno do jednotlivých kontigů a 3 byly sestaveny do čtyř nebo méně kontigů.
4. Soustruh byl dále aplikován na vzorky stolice, které vytvořily 20 cirkularizovaných genomů, včetně Prevotella copri a kandidáta Cibiobacter sp., které byly známé tím, že byly bohaté na mobilní genetické prvky.
Hlavní úspěch
Extrakční protokol pro HWM DNA
Střevní metagenomické studie založené na dlouhém čtení sekvenování již dlouho trpí tvrdostí při extrahování DNA o vysoké molekulové hmotnosti (HMW) ze stolice.V této studii byl zaveden protokol extrakce na bázi enzymu, aby se předešlo rozsáhlému střihu při narážení kuliček tradičními metodami.Jak je znázorněno na následujícím obrázku, vzorky byly nejprve ošetřeny koktejlem enzymů, včetně lytického enzymu, MetaPolyzymu atd., aby došlo k degradaci buněčných stěn.Uvolněná DNA byla extrahována systémem fenol-chloroform, následovalo štěpení proteinázou K a RNázou A, čištění na koloně a výběr velikosti SPRI.Touto metodou se podařilo získat mikrogramy HMW DNA z 300 m stolice, což splňuje požadavky na dlouhodobé sekvenování z hlediska kvality i kvantity.
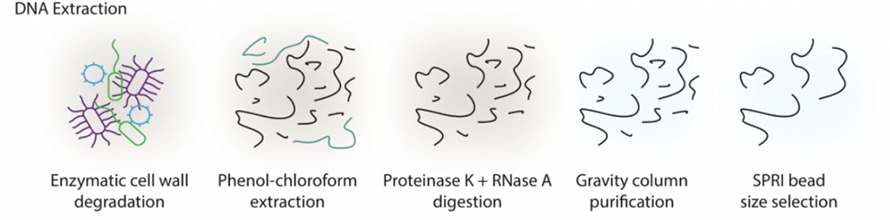
Obrázek 1. Schéma extrakce HWM DNA
Schéma toku soustruhu
Jak je popsáno na následujícím obrázku, Soustruh obsahuje existující proces surového basecalling procesu pomocí Guppy.Dvě sestavy s dlouhým čtením jsou pak vyrobeny společnostmi Flye a Canu odděleně a následuje detekce a odstranění chybné sestavy.Dvě podsestavy jsou sloučeny pomocí rychlého sloučení.Po sloučení jsou velké sestavy na úrovni megabází kontrolovány na cirkularizaci.Následně je zpracováno konsensuální upřesňování těchto sestav pomocí krátkých čtení.Konečné sestavené bakteriální genomy jsou zpracovány pro konečnou detekci a odstranění chybného sestavení.
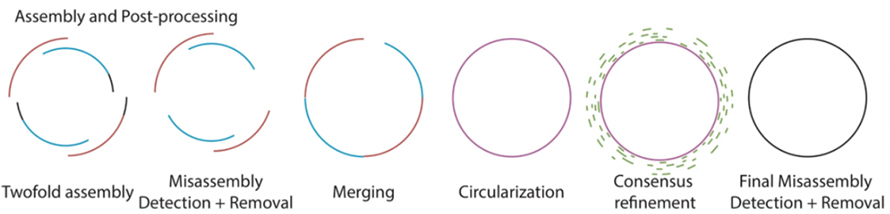
Obrázek 2. Schéma toku sestavy Soustruhu
Hodnocení soustruhu se směsí falešných bakterií
Standardní směs ATCC 12 druhů obsahující jak grampozitivní, tak gramnegativní bakterie byla použita k vyhodnocení výkonu platformy pro sekvenování nanopórů a soustruhu v sestavě MAG.Nanopore platforma s N50 o velikosti 5,9 kb vygenerovala celkem 30,3 Gb dat.Soustruh výrazně zlepšil montáž N50 na 1,6 až 4krát ve srovnání s jinými montážními nástroji s dlouhým čtením a 2 až 9krát ve srovnání s hybridními montážními nástroji.Z 12 bakteriálních genomů bylo sedm sestaveno do jednotlivých kontigů (obrázek 3. Circos s černou tečkou).Tři další byly sestaveny do čtyř nebo méně kontigů, ve kterých nejnekompletnější sestava obsahovala 83 % genomu v jednom kontigu.
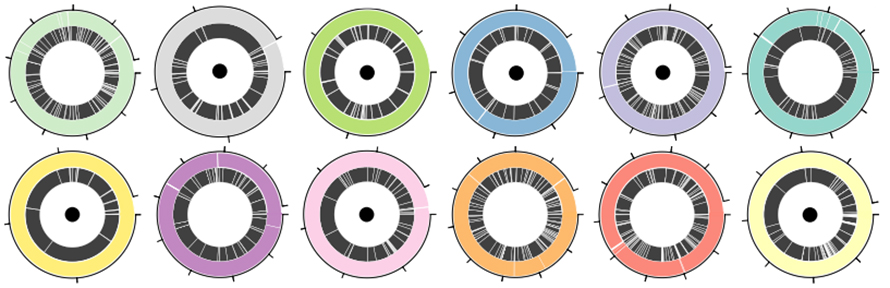
Obrázek 3. Uspořádání genomu v definované 12druhové bakteriální směsi
Aplikace soustruhu ve vzorcích stolice
Tato metoda byla dále aplikována na vzorky lidské stolice za účelem srovnání identifikace organismu a kontinuity sestavování se stávajícími metodami, read-cloud a analýzou založenou na krátkém čtení.Ze tří zahrnutých vzorků poskytla nová enzymatická extrakce alespoň 1 μg na 300 mg vstupní hmoty.Sekvenování nanopórů těchto HMW DNA generovalo dlouhé čtení s N50 o 4,7 kb, 3,0 kb a 3,0 kb, v daném pořadí.Je pozoruhodné, že současná metoda ukázala velký potenciál v mikrobiální detekci ve srovnání s existujícími metodami.Zde byla prokázána relativně vyšší druhová diverzita alfa ve srovnání s short-read a read-cloudem.Kromě toho byly touto metodou získány všechny rody z analýzy krátkého čtení, dokonce i typicky grampozitivní organismy odolné vůči lýze.
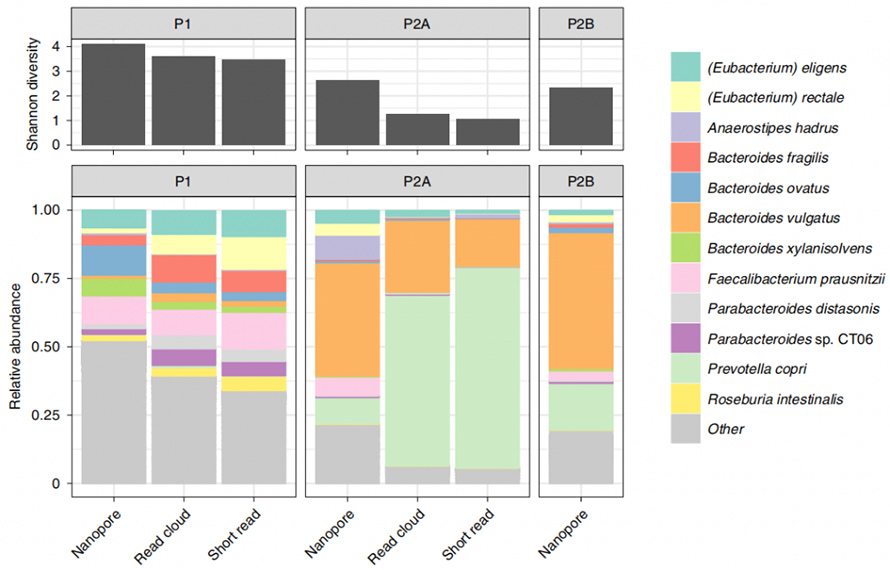
Obrázek 4. Alfa diverzita a taxanomické složky určené metodami Nanopore, short-read a read-cloud
Soustruh poskytl mnohem delší celou sestavu N50 než sestava short-read a read-cloud, a to i přes troj- až šestinásobně nižší vstup nezpracovaných dat.Návrhy genomů byly vytvořeny metodou contig binning, ve které byly návrhy klasifikovány na „vysoce kvalitní“ nebo „částečné“ na základě úplnosti, kontaminace, genů jádra s jednou kopií atd. Sestavení dlouhého čtení ukázalo mnohem vyšší spojitost při nižších nákladech ve srovnání na short-read a read-cloud.
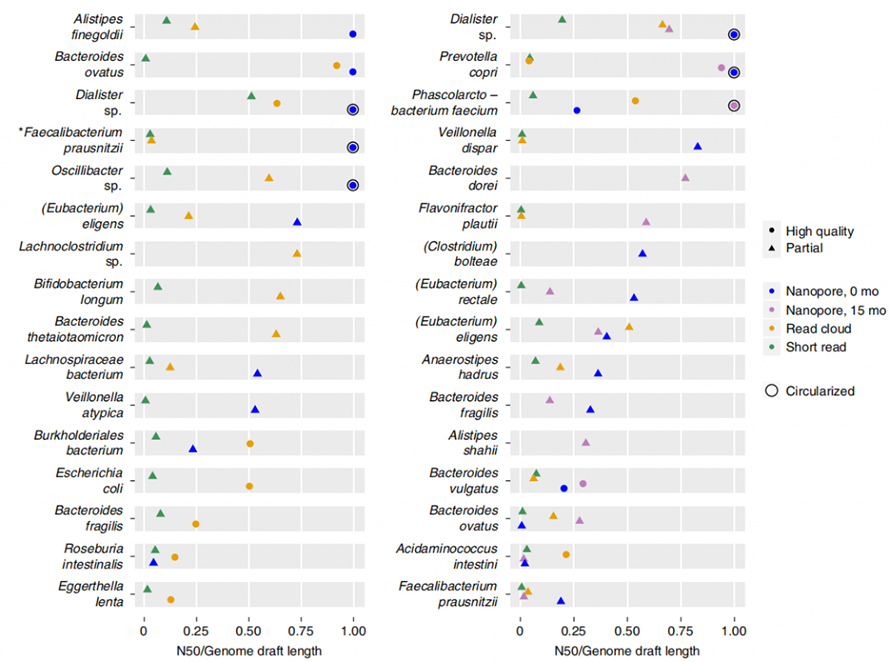
Obrázek 5. Souvislost sestavení na organismus každé metody
Kromě toho je současný přístup k sestavení schopen poskytnout uzavřené, kruhové genomy.Ve vzorcích stolice bylo sestaveno osm vysoce kvalitních, jednosložkových genomů a pět z nich dosáhlo přesné cirkularizace.Přístup dlouhého čtení také ukázal působivou kapacitu při řešení opakujících se prvků v genomech.CircularizedP. coprigenom byl vytvořen tímto přístupem, o kterém je známo, že obsahuje vysoký stupeň opakování sekvence.Nejlepší sestavení tohoto genomu pomocí short-read a read-cloud nikdy nepřesáhlo N50 130 kb, a to ani s hloubkou pokrytí 4800X.Tyto prvky s vysokým počtem kopií byly plně vyřešeny přístupem dlouhého čtení, který se často nacházel v bodech zlomu sestav pro krátké čtení nebo čtení-cloud.V této studii byl popsán další uzavřený genom, o kterém se věřilo, že je členem nedávno popsanéhoCibiobacterklad.V této uzavřené sestavě bylo identifikováno pět domnělých fágů v rozsahu od 8,5 do 65,9 kb.
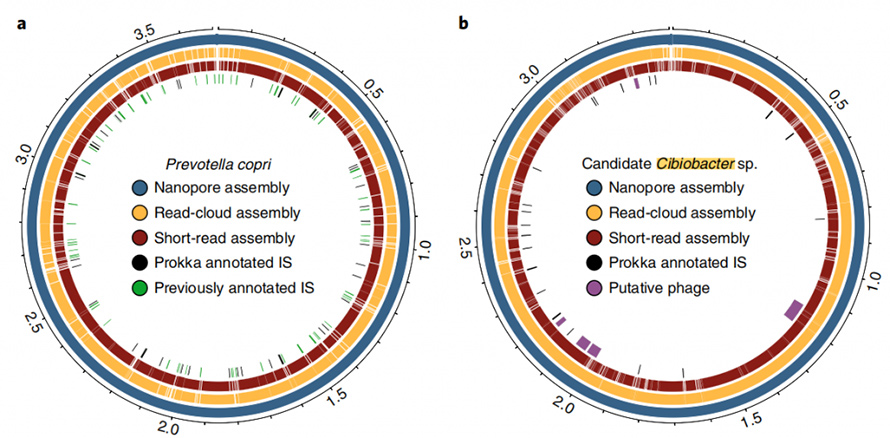
Obrázek 6. Circos diagram uzavřených genomů P.copri a Cibiobacter sp.
Odkaz
Moss, EL, Maghini, DG, & Bhatt, AS (2020).Kompletní, uzavřené bakteriální genomy z mikrobiomů pomocí sekvenování nanoporů.Přírodní biotechnologie,38(6), 701-707.
Tech and Highlights si klade za cíl sdílet nejnovější úspěšnou aplikaci různých vysoce výkonných sekvenačních technologií v různých oblastech výzkumu a také skvělé nápady v experimentálním designu a dolování dat.
Čas odeslání: leden-07-2022