Illumina и BGI



Характеристика
●Платформи:Illumina NovaSeq 6000, NovaSeq, HiSeq X Ten и BGI-DNB-T7
●Режими на последователност:PE50, PE100, PE150, PE250
●Контрол на качеството на библиотеките преди секвениране
●Подреждане на доставка на данни и QC:доставка на QC отчет и необработени данни във формат fastq след демултиплексиране и филтриране на Q30 четения.
Предимства на услугата
●Гъвкавост на услугите за секвениране:клиентът може да избере последователност по лента, поточна клетка или количество данни.
●Универсалност на платформите:DNB библиотеките могат да бъдат прехвърлени към платформите на Illumina
●Обширен опит в платформата за секвениране на Illumina:с хиляди затворени проекти с различни видове.
●Доставка на QC доклад за секвениране:с показатели за качество, точност на данните и цялостно изпълнение на проекта за секвениране.
●Зрял процес на секвениране:с кратко време за изпълнение.
●Строг контрол на качеството: прилагаме строги изисквания за контрол на качеството, за да гарантираме предоставянето на постоянно висококачествени резултати.
Примерни изисквания*
Частична последователност на лентите
| Количество данни (X) | Концентрация (qPCR/nM) | Сила на звука |
| X ≤ 50 Gb | ≥ 2 nM | ≥ 20 μl |
| 50 Gb ≤ X < 100 Gb | ≥ 3 nM | ≥ 20 μl |
| X ≥ 100 Gb | ≥ 4 nM | ≥ 20 μl |
Единична лента (Illumina)
| Платформа | Концентрация (qPCR/nM) | Сила на звука |
| HiSeq X Ten | ≥ 2 nM | ≥ 20 μl |
| NovaSeq 6000 SP | ≥ 1 nM | ≥ 25 μl |
| NovaSeq 6000 S4 | ≥ 1,5 nM | ≥ 25 μl |
| NovaSeq X | ≥ 1,5 nM | ≥ 25 μl |
| BGI-DNBSEQ-T7 | ≥ 1,5 nM | ≥ 25 μl |
В допълнение към концентрацията и общото количество е необходим и подходящ пиков модел.
Моля, свържете се с нас, ако вашите проби не отговарят на изискванията за изходен материал.
Работен процес на услугата
Контрол на качеството на библиотеката

Секвениране

Контрол на качеството на данните

Доставка на проект
Доклад за QC на библиотеката
Предоставя се отчет за качеството на библиотеката преди секвениране, оценка на количеството на библиотеката и фрагментиране.
QC доклад за секвениране
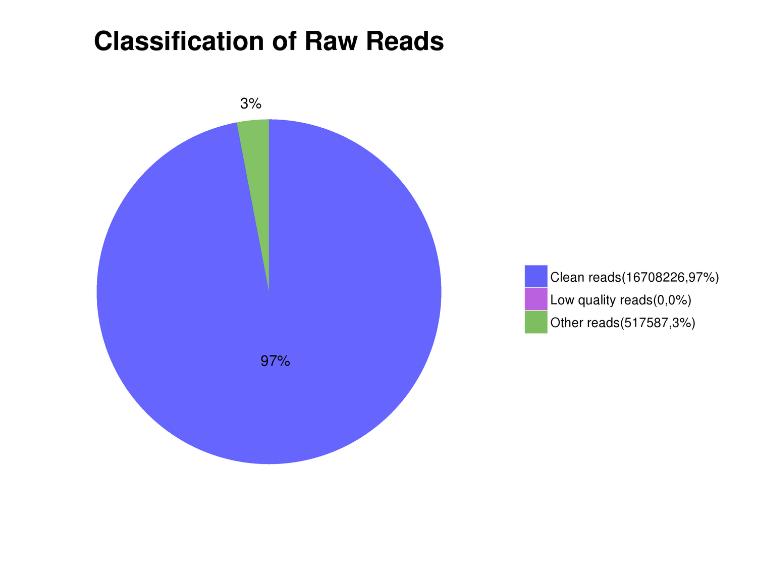
Таблица 1. Статистически данни за секвениране на данни.
| Примерен идентификатор | BMKID | Сурови четения | Сурови данни (bp) | Чисто четене (%) | Q20 (%) | Q30(%) | GC (%) |
| C_01 | BMK_01 | 22,870,120 | 6 861 036 000 | 96,48 | 99.14 | 94,85 | 36,67 |
| C_02 | BMK_02 | 14,717,867 | 4,415,360,100 | 96,00 | 98,95 | 93,89 | 37.08 |
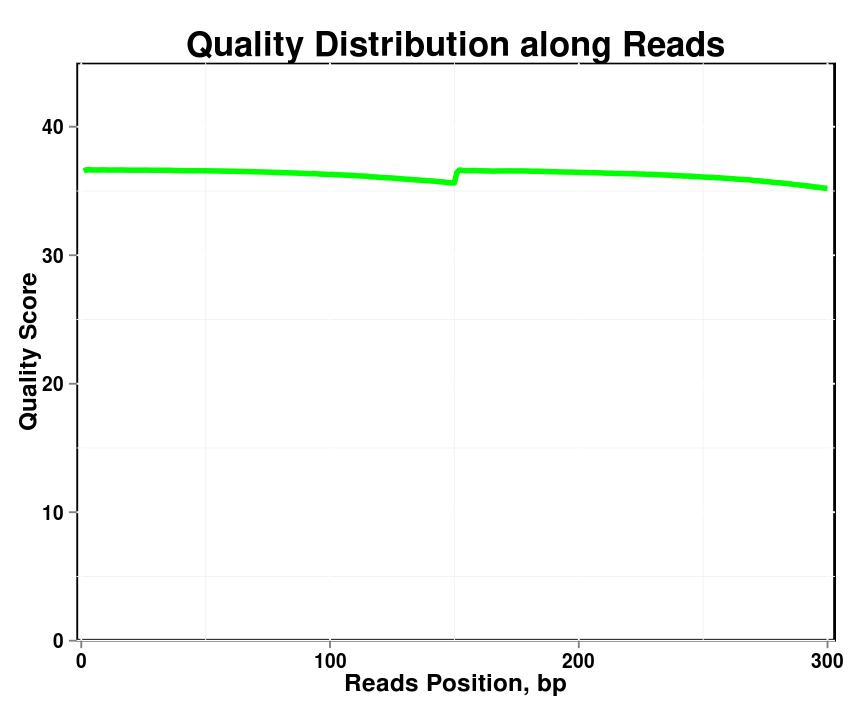
Фигура 1. Разпределение на качеството по отчитанията във всяка проба
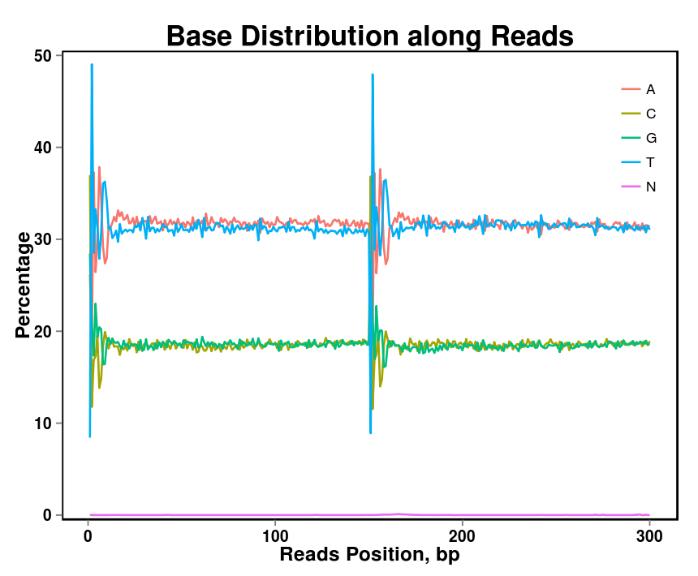
Фигура 2. Базово разпределение на съдържанието
Фигура 3. Разпределение на прочетеното съдържание в данните за последователност